深度学习的基本知识
公式使用MathJax引擎显示
线性和非线性。
线性认为是一次曲线,如\(y={kx+b}\)。非线性可以认为是二次曲线,如\(y={kx^2+b}\)
正则化
正则化就是:损失函数+\(\Delta w\)。加上\(\Delta w\)的目的就是使函数更加平滑。\(\Delta w\)是正则项。
什么叫平滑,即允许有部分误差,但是参数w要很小。输入可以很大,但是输出变化很小。
线性模型定义
线性模型不仅仅只是是线性关系(即一条直线),而且是参数(即w)对输出是线性的,即有可能是\(y = w_1x+w_2x+…+…\)
什么是线性不可分?
举个例子,二维平面上有两类点,无法用一条一维直线将其完全分开;N维空间中有两类点,用N-1维的分隔超平面无法将两类点完全分开,就叫做线性不可分。
凸优化和非凸优化。
凸函数如下图所示
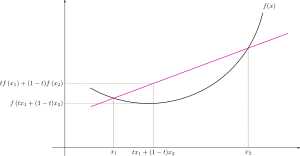
判断一个最优化问题是不是凸优化问题一般看以下几点:
- 目标函数\(f\)如果不是凸函数,则不是凸优化问题
- 决策变量\(x\)中包含离散变量(0-1变量或整数变量),则不是凸优化问题
- 约束条件写成\(g(x)\leq0\)时,\(g\)如果不是凸函数,则不是凸优化问题,\(g(x)=\)一次函数-二次函数
为什么要区分凸优化和非凸优化问题?
凸优化问题中局部最优解同时也是全局最优解,非凸优化可行域集合可能存在无数个局部最优点,通常求解全局最优的算法复杂度是指数级的(NP难)
目前深度学习算法的目标函数,几乎全都是非凸的。而目前寻找最优解的方法,都是基于梯度下降的。梯度下降方法是解决不了非凸问题的。深度结构带来的非凸优化仍然不能解决,这限制着深度结构的发展
用ReLU激活函数来避免梯度消失/爆炸的问题。
Pre-training
关于Pre-Training的最好的理解是,它可以让模型分配到一个很好的初始搜索空间
Hinton在DBN(深信度网络)中,则是利用此假设,提出了逐层贪心初始化的方法,进行实验:
①Stage 1:先逐层用RBM使得参数学习到有效从输入中提取信息。进行生成模型P(X)。(Pre-Training)。
②Stage 2: 利用生成模型得到的参数作为搜索起点,进行判别模型P(Y|X)。(Fine-Tuning)。
RBM-Pre-training网络训练模型的过程可以看做对一个深层BP网络权值参数的初始化,使DBN克服BP网络因随机初始化权值参数而容易陷入局部最优和训练时间过长的问题点。
稀疏自动编码器(sparse autoencoder)堆叠得到栈式自动编码器(stacked autoencoders),RBM堆叠得到DBN;而且二者都可以被用来做有监督DNN的预训练,用的还都是同样的无监督逐层预训练方法,二者实际上也都是起到了特征探测器的作用,都是给定一个输入,得到一个中间层,并利用中间层去重构一个和输入相同的样本,然后利用不同的评价指标,通过某种优化方法,尽可能的缩小输出样本和输入样本之间的差异。那它们的区别在什么地方呢?
首先Autocoder是一个确定模型,它的输入和输出之间有着严格的数学公式;而RBM源于BM,源于玻尔兹曼分布,是一个基于概率的不确定模型。
Autocoder训练时采用BP算法,直接做梯度下降(看成只有一层的BP神经网络),而RBM采用CD-k算法,只能利用k次吉布斯采样的结果去近似的计算梯度。
BP算法和梯度下降法
BP算法实际上就是应用在多层网络中的梯度下降算法,原理与梯度下降算法相同,但区别在于BP算法需要求不同层连接所对应的梯度,而不是像普通的梯度下降算法那样,只需处理一层的问题。
梯度下降算法与随机梯度下降算法
- 梯度下降算法在更新参数时,遍历所有的样本
- 随机梯度下降算法每一次更新参数,不必遍历所有的训练集合,可以仅使用一个数据进行更新。这样做不如梯度下降的精确度高,但是整体走向最小值
- 结合梯度下降算法+随机梯度下降算法,提出了mini-batch方法
过拟合
简单的说过拟合就是在训练集上训练很好但是在测试集上训练很差
损失函数
熵是一个不确定性的测度,也就是说,我们对于某件事情知道得越多,那么,熵就越小,因而对于试验的结果我们越不感到意外。
交叉熵的概念就是用来衡量估计模型与真实概率分布之间的差异情况的。
与方差误差函数一样,交叉熵函数同样拥有两个性质,一个是非负性,一个是当真实输出a与期望输出y接近时,损失函数的函数值接近于0。另外,它可以克服方差代价函数更新权重过慢的问题。
- 二次代价函数,其中\(y(x)\)表示实际值,\(a\)表示网络输出值,\(n\)表示训练样本数:

一般的,对于一个样本且以softmax函数作为输出层,那么损失函数为:
\(C = - \sum_{i}^{ }(y_{i}lna_{i})\)
- 交叉熵代价函数,\(z\)表示神经元的输入, \(\sigma\)表示激活函数:

其中\(\omega \)的梯度公式,\(a=\sigma (z)\):

二次代价函数和交叉熵代价函数比较:
对于二次代价函数:初始的代价(误差)越大训练越慢 与 希望的错误越大改正的幅度越大从而学习得越快的期望不符
对于交叉熵代价函数:该梯度公式中的\(\sigma(z)-y\)表示网络输出值与实际值之间的误差。当误差越大,梯度就越大,参数\(w\)调整得越快,训练速度也就越快。
实际情况表明,交叉熵代价函数的训练效果比二次代价函数要好
通常情况下,当输出层的激活函数使用softmax时,选择交叉熵,隐藏层的激活函数与输出层的激活函数无关
对于输出层的激活函数,若是二分类问题可以选择sigmoid函数,多分类问题选择softmax函数
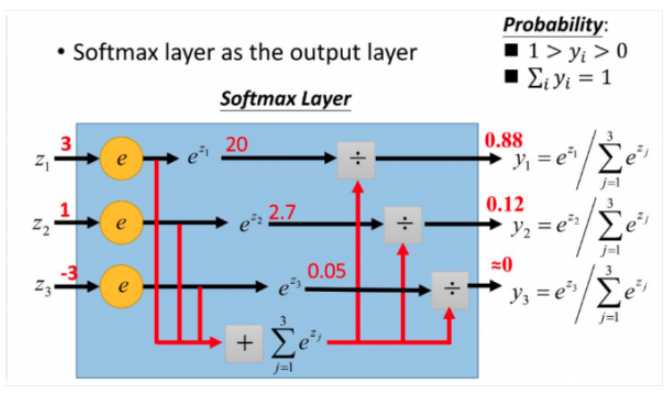
softmax函数
假设我们有j个神经元,第i个神经元的输出值为i,那么这个神经元的softmax值\(a_i\)为:
\(a_{i} = \frac{e^{i}}{\sum_{j}^{ }e^{j}}\)
更加形象的如下图所示:
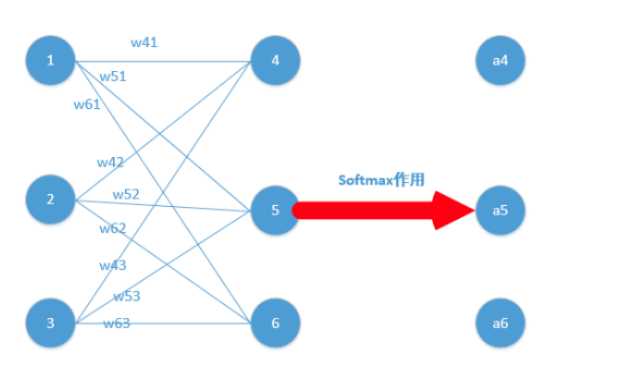
对于softmax函数求导,给出一个简单例子,如下图所示,该图只显示了隐含层和输出层
损失函数如下:
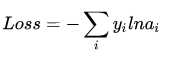
其中y代表真实值,a代表softmax求出的值,又由于输出层使用的是one-hot编码,假设真实输出的第j个为1,那么:
对\(w_{jk}\)求偏导,\(z_{k}\)为\(net_{k}\),\(net_{k} = \sum w_{jk}x_{j}\):
$$\frac{\partial L}{\partial w_{jk}} = \frac{\partial L}{\partial a_{k}}\frac{\partial a_{k}}{\partial z_{k}}\frac{\partial net_{k}}{\partial w_{jk}}$$
$$\frac{\partial L}{\partial w_{jk}} = - \frac{1}{a_{k}}\frac{\partial a_{k}}{\partial z_{k}}x_{j}$$
对于softmax函数,其并不是\(a_{k}\)对应与\(z_{k}\),而是\(a_{j} = z_{i},(i\neq j || i = j) \)
对于第一种情况 j = i:
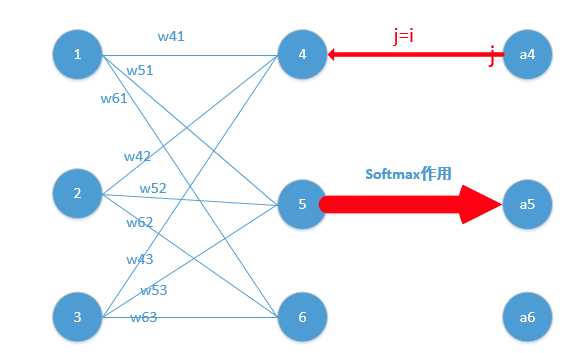
那么:
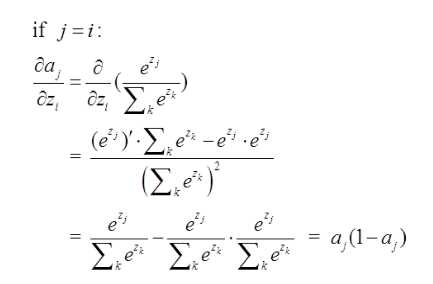
则:
$$\Delta w = \frac{\partial L}{\partial w_{jk}} = (a_{j}-1)x_{j}$$
对于第二种情况\(i\neq j\)
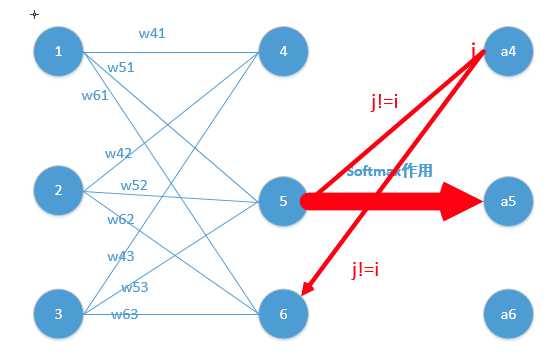
那么:
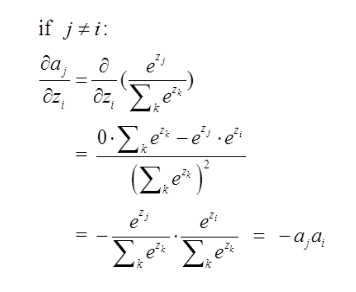
则:
$$\Delta w = \frac{\partial L}{\partial w_{jk}} = (a_{i})x_{j}$$
来个更直观的例子:
假设某个样本经过softmax函数作用后的概率为[0.0903,0.2447,0.665],如果样本正确的分类为第二个(即第一种情况i==j),那么计算出来的*偏导数就是[0.0903,0.2447-1,0.665]=[0.0903,-0.7553,0.665],然后再根据这个进行BP算法
mini-batch
问题引入:
考虑一个典型的有监督机器学习问题,给定m个训练样本\(S = \{ x^{i},y^{i} \} \),通过经验风险最小化来得到一组权值\(w\),则现在对于整个训练集待优化目标函数为:
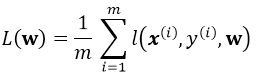
其中\(l(x^{i},y^{i},\mathbf{w})\)为单个训练样本\((x^{i},y^{i})\)的损失函数,单个样本的损失表示如下:
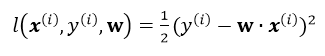
引入L2正则,即在损失函数中引入\(\frac{\lambda }{2}\left | \boldsymbol{w} \right |^{2}\),那么单个样本的最终损失函数为:
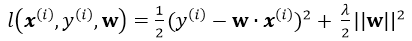
Batch Gradient Descent(BGD)
有了以上基本的优化公式,就可以用Gradient Descent 来对公式进行求解,假设\(w\)的维度为n,首先来看标准的Batch Gradient Descent算法:
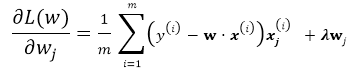
repeat until convergency{
for j=1;j<n ; j++:
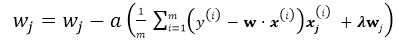
}
这里的批梯度下降算法是每次迭代都遍历所有样本,由所有样本共同决定最优的方向。
Stochastic Gradient Descent(SGD)
随机梯度下降就是每次从所有训练样例中抽取一个样本进行更新,这样每次都不用遍历所有数据集,迭代速度会很快,但是会增加很多迭代次数,因为每次选取的方向不一定是最优的方向.
repeat until convergency{
random choice j from all m training example:
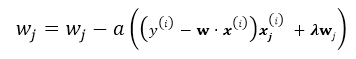
}
mini-batch Gradient Descent
这是介于以上两种方法的折中,每次随机选取大小为b的mini-batch(b<m), b通常取10,或者(2…100),这样既节省了计算整个批量的时间,同时用mini-batch计算的方向也会更加准确。
repeat until convergency{
for j=1;j<n ; j+=b:
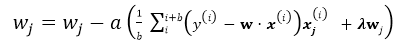
}
优化方法
在训练时优化模型
- 选择合适的损失函数
- mini-batch
- 新的激活函数(ReLU,在小范围是线性,其余是非线性)
- 自适应学习率(Adam)
- momentum
在测试时优化模型
- Early Stopping
- 正则化(Weight Decay)
- Dropout(overfitting,即training效果好,Testing效果不好,增加Testing的效果)
- 网络结构
Dropout
训练的时候是p% sampling , 测试的时候是不dropout,并且所有的权重*(1-p%)