卷积神经网络-CNN
卷积神经网络使用范围
- 画面不变性(invariance),即该画面部分特征保持不变,我们知道一个物体不管在画面左侧还是右侧,都会被识别为同一物体,这一特点就是不变性(invariance)。
- 平移不变性
- 旋转不变性
- 大小不变性
- 亮度不变性

若使用传统的前馈神经网络来图片进行训练,我们用数字(16进制)对图片中的每一个像素点(pixel)进行编号。 当使用右侧那种物体位于中间的训练数据来训练网络时,网络就只会对编号为5,6,9,a的节点的权重进行调节。 若让该网络识别位于右下角的“横折”时,则无法识别。
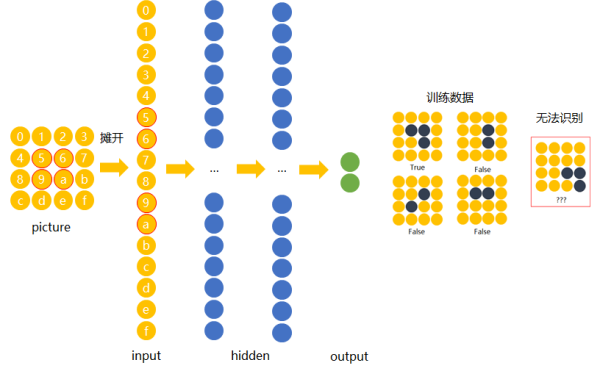
解决办法是用大量物体位于不同位置的数据训练,同时增加网络的隐藏层个数从而扩大网络学习这些变体的能力。
然而这样做十分不效率,为什么相同的东西在位置变了之后要重新学习?有没有什么方法可以将中间所学到的规律也运用在其他的位置? 换句话说,也就是让不同位置用相同的权重。
卷积神经网络
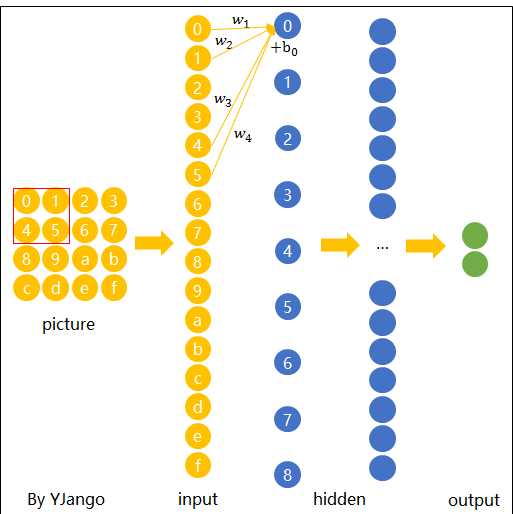
卷积神经网络就是让权重在不同位置共享的神经网络。
当filter扫到其他位置计算输出节点\(y_{i}\) 时,\(w_{1},w_{2},w_{3},w_{4}\),包括\(b_{0}\)是共用的。
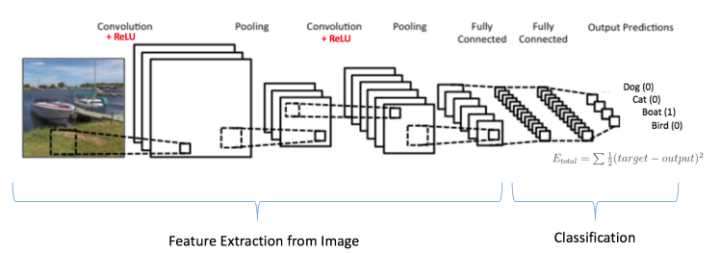
神经网络大致结构如下,主要就是卷积层,ReLU层,池化层和最后的全连接层:
Zero padding
Zero padding可以帮助控制Feature Map的输出尺寸,同时避免了边缘信息被一步步舍弃的问题。
例如:下面4x4的图片在边缘Zero padding一圈后,再用3x3的filter卷积后,得到的Feature Map尺寸依然是4x4不变。

为什么选择3x3的filter或5x5的filter?
选择3x3的filter和1的zero padding,或5x5的filter和2的zero padding既可以保持图片的原始尺寸,又考虑到了像素与其距离以内的所有其他像素的关系。
Filter与channel的区别?
对于depth只有1的灰度图来说,每个Filter就是一个channel(channel跟原始图的灰度有关)。对于depth为n的图像,每个filter由n个channel组成
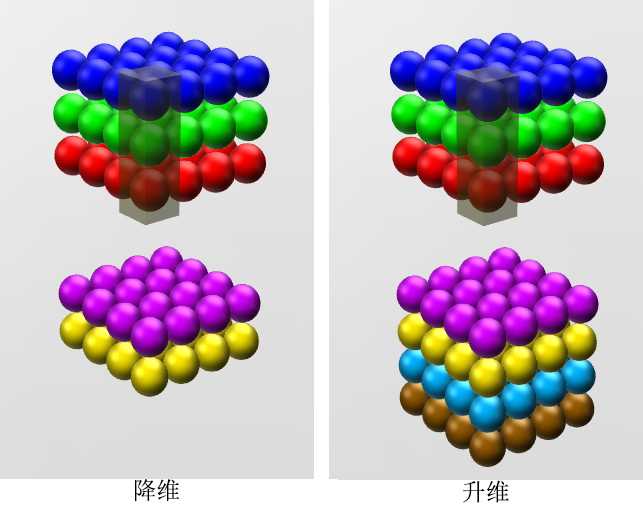
1x1卷积核(filter)
- 若卷积的输入输出都只是一个平面,那么1x1卷积核并没有什么意义
- 若卷积的输入输出是长方体(即depth>1),那么1x1卷积核不仅保留了图片的原有平面结构还调整了depth,从而完成了升维或降维的功能。
如下图所示,如果选择2个filters的1x1卷积层,那么数据就从原本的depth 3 降到了2。若用4个filters,则起到了升维的作用。
卷积神经网络推导
BP算法
由于卷积神经网络有更多的参数,所以会与全连接网络的BP算法推导有所不同。与本文之前的BP算法推导有所不同,为了更加详细的描述卷积神经网络的推导,本文还加上了偏置b,即:
$$\mathbf{x}^{l} = f(\mathbf{net}^{l}), 其中\mathbf{net}^{l} = \mathbf{W}^{l}\mathbf{x}^{l-1}+\mathbf{b}^{l}$$
建议先把前一章的关于BP算法推导给看完后再看卷积神经网络的推导。
对于偏置b求偏导得:
$$\frac{\partial E}{\partial \mathbf{b}} = \frac{\partial E}{\partial \mathbf{net}^{l}}\frac{\partial \mathbf{net}^{l}}{\partial \mathbf{b}} = \delta$$
即偏置\(b\)的偏导\(=\)误差\(E\)对一个节点的全部输入的导数,\(\delta\)可以表示灵敏度,即基b变化多少,误差就会变化多少:
$$\delta = \frac{\partial E}{\partial \mathbf{b}} = \frac{\partial E}{\partial \mathbf{net}^{l}}$$
对于权值\(\mathbf{w}\)在隐藏层求偏导得,其中◦表示点积:
$$\frac{\partial E}{\partial \mathbf{W}^{l}} = \frac{\partial E}{\partial \mathbf{net}^{l}}\frac{\partial \mathbf{net}^{l}}{\partial \mathbf{W}^{l}} = \frac{\partial E}{\partial \mathbf{net}^{l}}\mathbf{x}^{l-1}$$
$$\frac{\partial E}{\partial \mathbf{net}^{l}} = \frac{\partial E}{\partial \mathbf{net}^{l+1}}\frac{\partial \mathbf{net}^{l+1}}{\partial \mathbf{net}^{l}} = \frac{\partial E}{\partial \mathbf{net}^{l+1}}\frac{\partial \mathbf{net}^{l+1}}{\partial f(\mathbf{net}^{l})}\frac{\partial f(\mathbf{net}^{l})}{\partial \mathbf{net}^{l}} = \mathbf{\delta}^{l+1}(\mathbf{W}^{l+1})^{T}◦f^{`}(\mathbf{net}^{l})$$
令:
$$\mathbf{\delta} ^{l} = (\mathbf{W}^{l+1})^{T}\mathbf{\delta}^{l+1}◦f^{`}(\mathbf{net}^{l})$$
同理对于输出层,灵敏度如下,其损失函数为平方差:
$$\mathbf{\delta} ^{l} = f^{`}(\mathbf{net}^{l}) ◦ (\mathbf{y}^{n}-\mathbf{t}^{n})$$
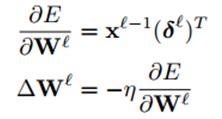
卷积神经网络
卷积层权值更新
一个输出map可能是多个输入maps的累加值,\(x_{i}^{l-1}\)表示卷积层l层的输入(即l-1层的输出)。\(M_{j}\)表示选择的输入maps的集合。
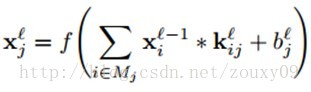
对于一个特定的输出map,每个输入maps的卷积核是不一样的。
假设每个卷积层l后都会接一个下采样层l+1。参考BP算法,需求出l层的每一个神经节点的灵敏度\(\delta \),BP算法求\(\delta \)如下:
$$\mathbf{\delta} ^{l} = (\mathbf{W}^{l+1})^{T}\mathbf{\delta}^{l+1}◦f^{`}(\mathbf{net}^{l})$$
为了求卷积神经网络的\(\delta \),我们需要:
- 对l+1层的节点的灵敏度求和(即求\((\mathbf{W}^{l+1})^{T}\mathbf{\delta}^{l+1}\))
- 当前层l的该神经元节点的输入net的激活函数的导数值,即\(f^{‘}(net)\)
因为采样层的一个神经元对应卷积层输出的feature map的一片神经元,因此层l中的一个feature map的每个节点只与l+1层中的相应的feature map的一个节点连接,如下:
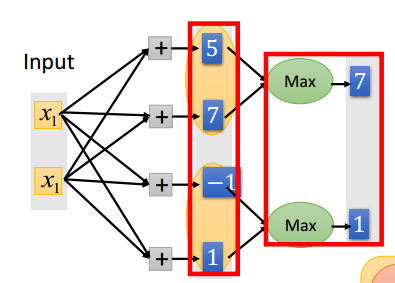
为了有效计算层l的灵敏度,我们需要上采样这个下采样层对应的灵敏度map(灵敏度map中每个像素对应一个灵敏度,所以也组成一个map),使得这个灵敏度map大小与卷积层的map大小一致,然后再将层l的map的激活值的偏导数与从第l+1层的上采样得到的灵敏度map逐元素相乘。
在下采样层map的权值都取一个相同值β,而且是一个常数。所以我们只需要将上一个步骤得到的结果乘以一个β就可以完成第l层灵敏度\(\delta \)的计算。
我们可以对每一个feature map重复相同的计算过程,且需要匹配相应的子采样层的map。公式如下:
$$\delta _{j}^{l} = \beta _{j}^{l+1}(f^{‘}(net_{j}^{l})◦up(\delta _{j}^{l+1}))$$
up(.)表示一个上采样操作。如果下采样的采样因子是n的话,它简单的将每个像素水平和垂直方向上拷贝n次。这样就可以恢复原来的大小了。实际上,这个函数可以用Kronecker乘积来实现:
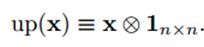
附Kronecker乘积:

计算偏置b的梯度,形如BP算法求偏置b的梯度:
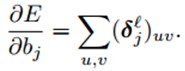
计算卷积核的权值梯度,由于很多连接的权值是共享的,因此,对于一个给定的权值,我们需要对所有与该权值有联系的点求梯度,然后对这些梯度求和,公式如下:
其中,\((p_{i}^{l-1})_{uv}\)是\(x_{i}^{l-1}\)在卷积时与\(k_{ij}^{l}\)逐元素相乘的patch,输出卷积map的(u, v)位置的值是由上一层的(u, v)位置的patch与卷积核\(k_{ij}\)逐元素相乘的结果。
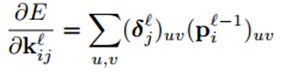
子采样层权值更新
对于子采样层来说,有N个输入maps,就有N个输出maps,只是每个输出map都变小了。其中l表示采样层,l-1表示卷积层:
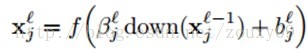
down(.)表示一个下采样函数。典型的操作一般是对输入图像的不同nxn的块的所有像素进行求和。这样输出图像在两个维度上都缩小了n倍。每个输出map都对应一个属于自己的乘性偏置β和一个加性偏置b。
- 采样层后接全连接层
使用BP算法来计算采样层的灵敏度map
- 采样层后接卷积层
这里最困难的是计算灵敏度map。一旦得到灵敏度map,那唯一需要更新的就是偏置参数β和b。
需要的参数:
- 找到当前层的灵敏度map中哪个patch对应于下一层的灵敏度map的给定神经元
- 乘以输入patch与输出像素之间连接的权值,即卷积核
以在matlab中的表示为例:
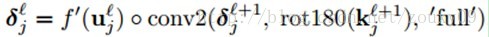
之后我们就可以计算b和β计算梯度了。
- 对于b,对灵敏度map中所有元素加起来就可以了:
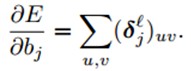
- 对于乘性偏置β,因为涉及到了在前向传播过程中下采样map的计算,所以我们最好在前向的过程中保存好这些maps,这样在反向的计算中就不用重新计算了:
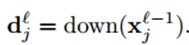
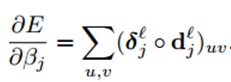
优化
Learning Combinations of Feature Maps 学习特征map的组合
大部分时候,通过卷积多个输入maps,然后再对这些卷积值求和得到一个输出map,这样的效果往往是比较好的,尝试去让CNN在训练的过程中学习这些组合,用\(α_{ij}\)表示在得到第j个输出map的其中第i个输入map的权值
Enforcing Sparse Combinations 加强稀疏性组合
为了限制一个输出map只与某些而不是全部的输入maps相连,在整体代价函数里增加稀疏约束项Ω(α)
其他有关卷积神经网络的信息,可参考