1. 机器学习
机器学习就是找到一个函数f,使得函数f:
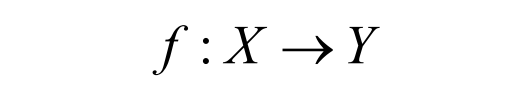
2. 特征
输入的向量每一维表示一些特征
3. Bias & Variance
Bias(偏差)
补充无偏估计概念:
设总体均值为\(\mu \),样本均值为\(\overline{x}\)
无偏估计就是:
\(E(\overline{x}) = \mu \)

上图中是unbiased(无偏差),即因为它是无偏估计的!!!

上图是biased estimator(有偏差的),因为它不符合无偏估计的定义
Variance (方差)
越不稳定,方差越大,越稳定,方差越小
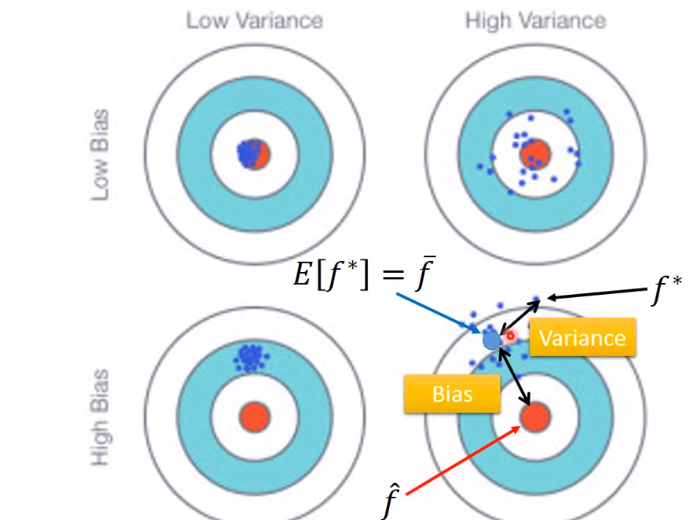
Bias和Variance判断

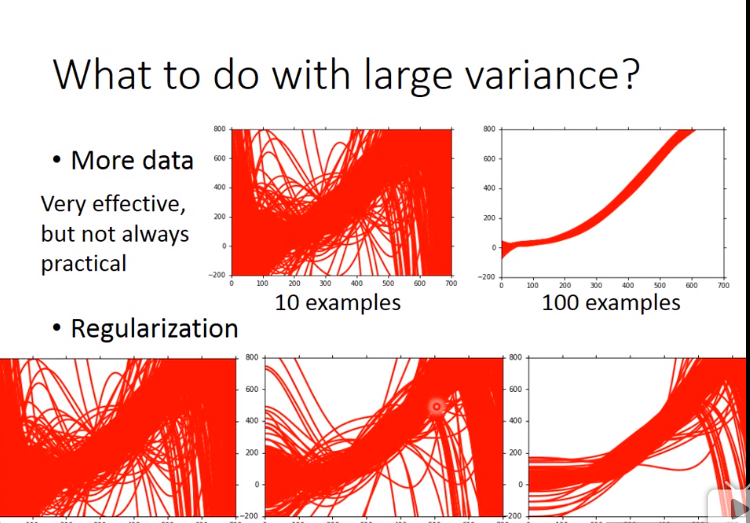
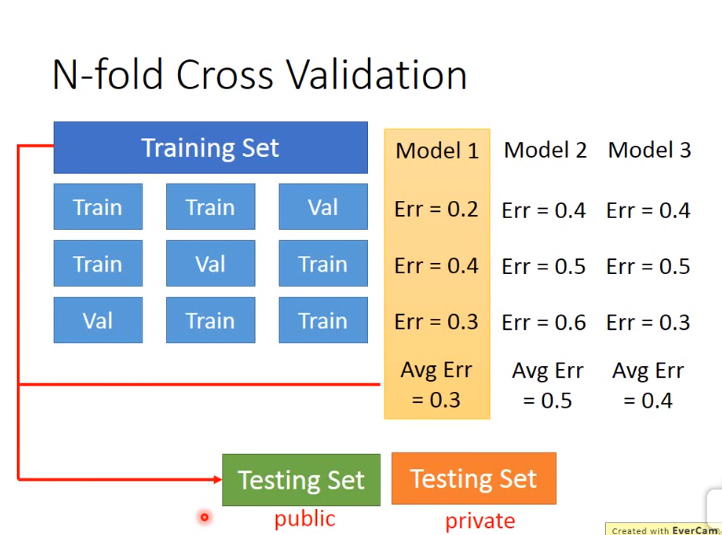
4. Regression(递归) VS Classification(分类) VS Prediction(预测)
- Regression: 输出是一个标量,即数值
举例: 预测PM2.5的值,该函数的输出是一个数值
- Classification
分类分为两种:二分类,多分类
二分类:输出结果为:Yes/No
多分类: 输出是一个类(one-hot vector)
- Structured Learning/Prediction
输出是一个序列,矩阵,图,树等等
5. 条件独立(Conditional independence)
条件独立的理解:
A,B 关于事件 C 条件独立:
- 事件 C 的发生,使本来不独立的事件 A 和事件 B 变得独立起来
- 事件 C 的出现或发生,解开了 A 和事件 B 的依赖关系
定义:
给定第三个事件C,如果P(A,B|C) = P(A|C)*P(B|C),则称A和B是条件独立事件,符号表示为\(A\perp B|Z\)
结论
P(A|B,C)=P(A|C)
证明,注意:P(A|B,C) = P(A|(B,C)):
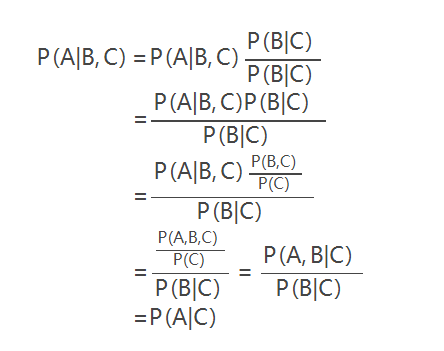
即只要 C 事件发生,A 和 B 之间便是独立的,A 发生与 B 发生没有关系
举例

条件独立应用

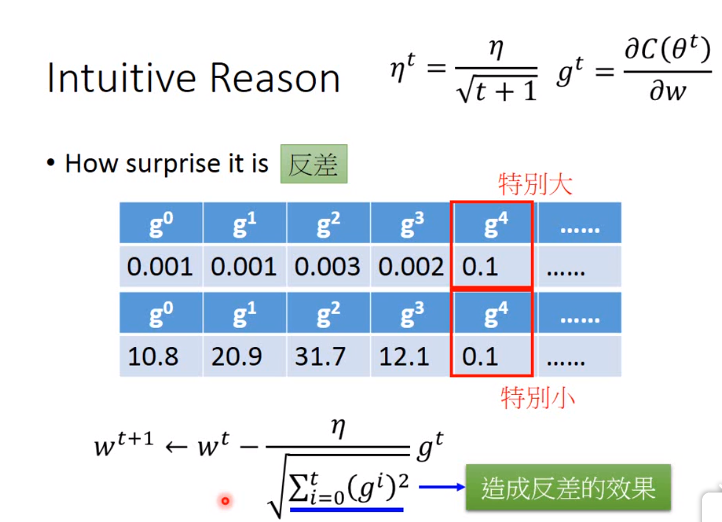
6. 自学习率算法–Adagrad
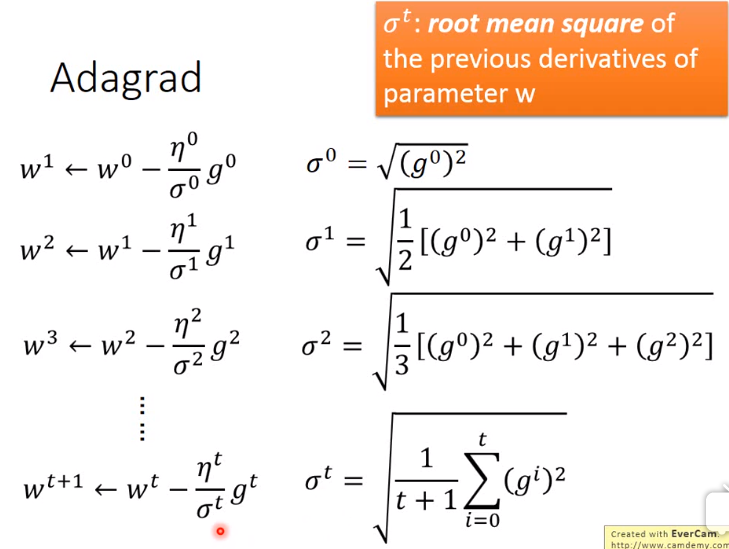
Adagrad每个参数的learning rate不一样。

如上图所示\(w^t\)表示一个参数,并不是一个向量,\(\sigma \)的算法如下图:
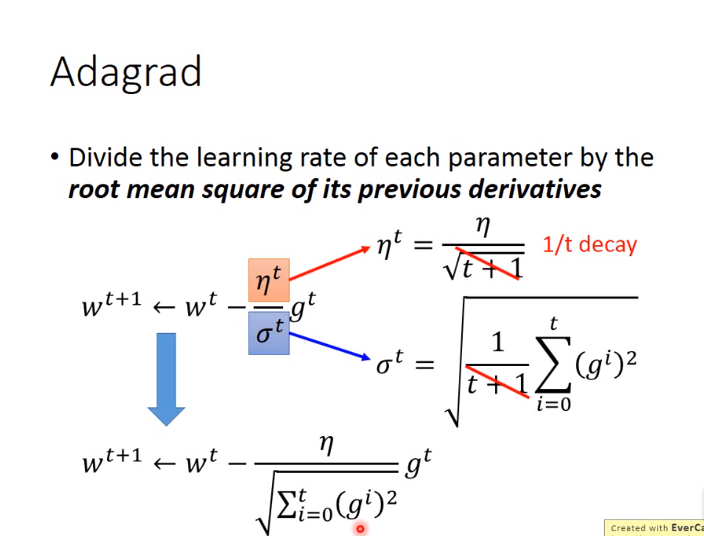
经过算数优化,最后可简写为:
对于Adagrad有一个疑惑,即随着梯度的增大,步长逐渐变小与之间的学习率梯度的增大,步长也增大有矛盾!
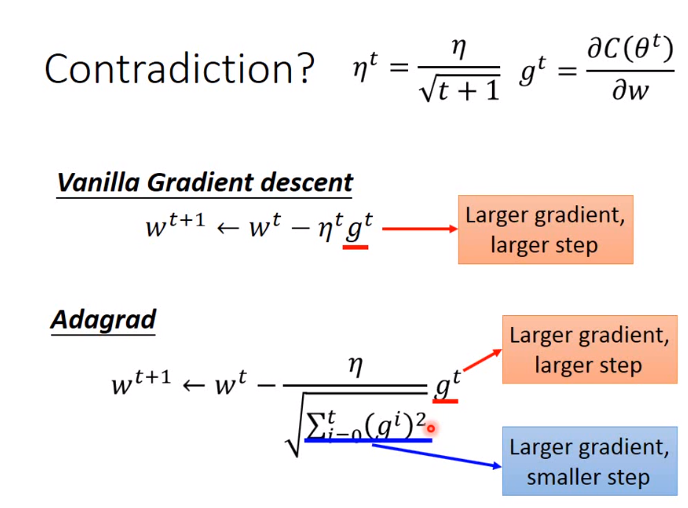
直观解释如下:
告诉我们现在的梯度与之前的梯度有多大的反差!!!,如下图:
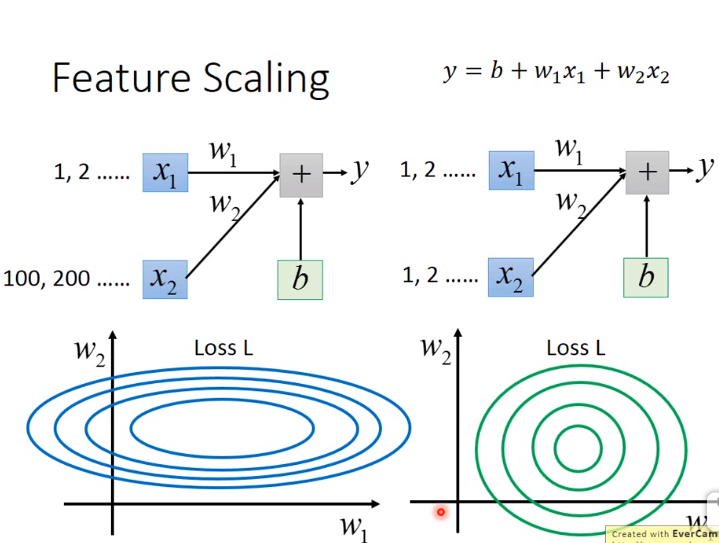
7. 特征缩放(Feature Scaling)
对于左图:
\(w_1\)的变化对y影响较小,所以比较平滑,也就是比较缓。\(w_2\)的变化对y影响较大,所以比较陡,也就是比较急。
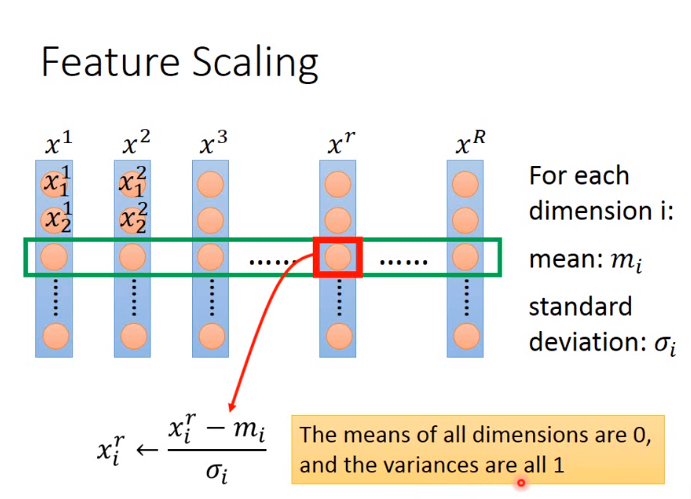
如下介绍一种正态化的方法来进行特征缩放:
8. 梯度下降理论基础
- 一. 首先根据二元的泰勒展开式,得如下图:

- 二. 然后将损失函数用泰勒展开式表示,其中a,b表示一个已知的点,如下图
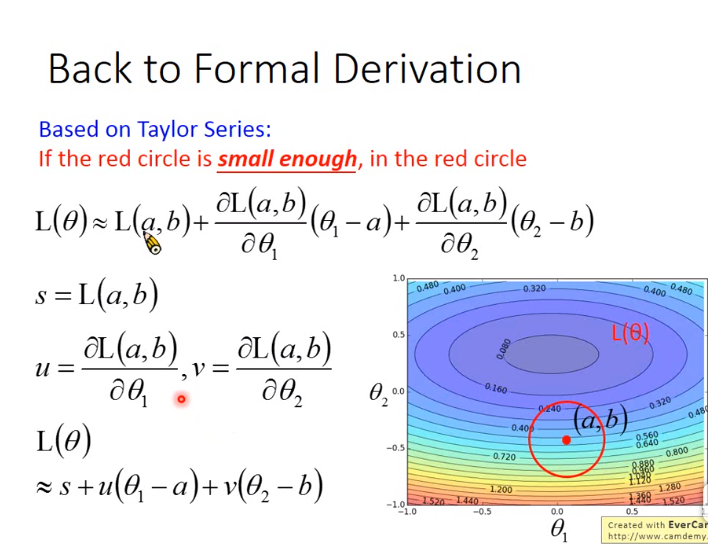
- 三. 得到用泰勒展开式表示的损失函数后,目标是在图中的红色小圈中找到\(\theta_1 \)和\(\theta_2 \),使得损失函数最小,如下图
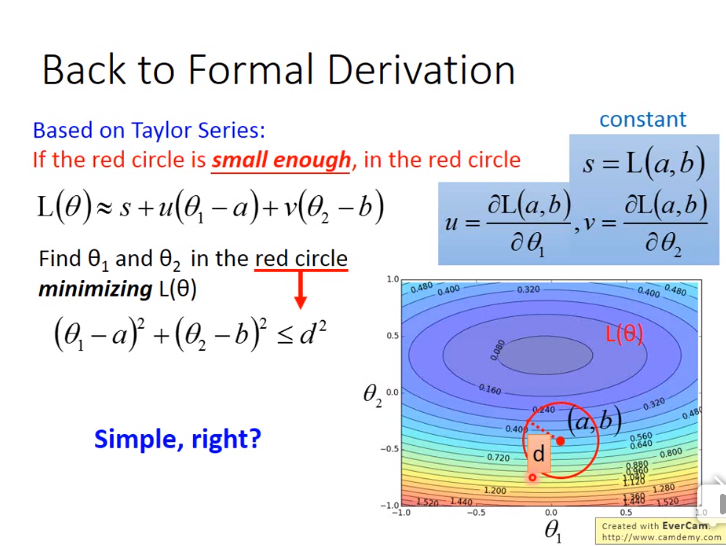
- 四. 再然后只需要把\((\Delta \theta_1 , \Delta \theta_2)\)和\(u,v\看做向量),然后如下图:

- 五. 只要泰勒展开式存在,那么才能计算梯度。如何确保泰勒展开式存在,即保证以(a,b)为圆心的红色圆圈足够小。如上图所示,即\(\eta\)与圆圈半径成正比。因此理论上\(\eta\)足够小,泰勒展开式才能成立,但是实际上很小泰勒展开式就成立了。如下图:

9. Classfication与Regression的区别
举例说明
如下图所示,把二分类问题作为一个回归问题进行求解(这是有问题的!)。训练时,class 1 -> 1,class 2 -> -1。那么测试时,越接近 1 -> class 1,越接近 -1 -> class 2。
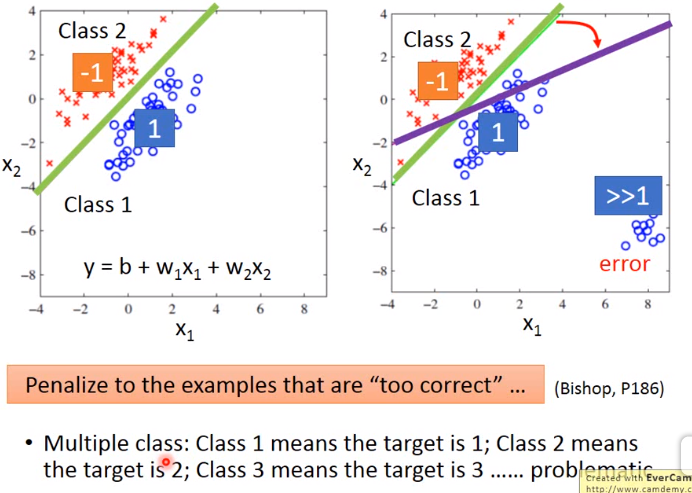
如上图左边那副图,对于该图的样本来说,其绿线很好的分隔的class 2和class 1。但是若遇到右图的样本,即有一部分样本 >> 1。那么在回归问题上其分隔线为紫线,因为紫线相比较于绿线越靠近样本,能减少误差。但是其实质是二分类问题,绿线才是正确的进行分类。所以可以看出二分类问题不能用回归问题进行求解。
10. 最大似然估计
已知某个随机样本满足某种概率分布,但是其中具体的参数不清楚,参数估计就是通过若干次试验,观察其结果,利用结果推出参数的大概值。最大似然估计是建立在这样的思想上:已知某个参数能使这个样本出现的概率最大,我们当然不会再去选择其他小概率的样本,所以干脆就把这个参数作为估计的真实值。
最大似然估计需要已知x和x对应的标签y,在不知道标签y的情况下可以使用EM算法
最大似然估计是利用已知的样本结果,在使用某个模型的基础上,反推最有可能导致这样结果的模型参数值。
如下图例题,即已知模型为正态分布,并且已知样本值,然后通过最大似然估计的方法求得正态分布的参数

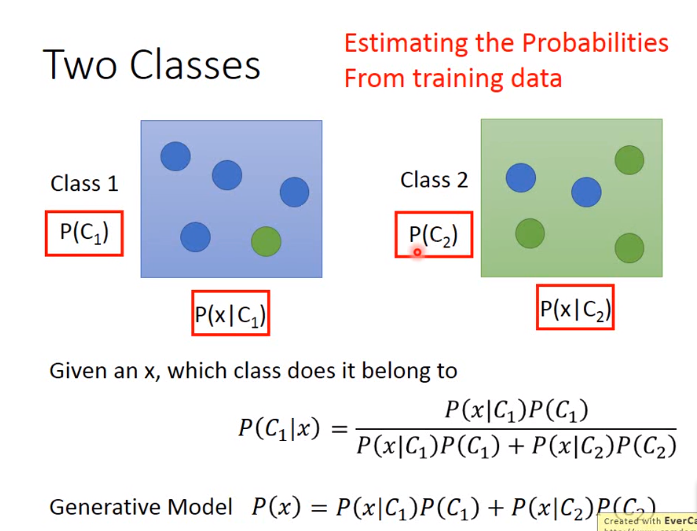
11. 如何进行分类(classfication)计算
如下图,已知x,求x的属于哪个class。其中生成模型就是x的概率,即P(x)。
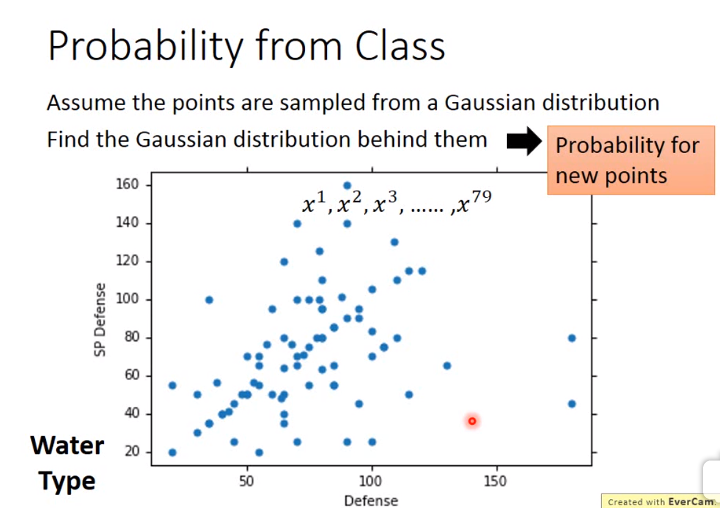
假设对于采样点是通过使用高斯分布进行采样,那么对于新的点的概率,我们只需要求得该高斯分布即可,即求得高斯分布的函数参数。为什么使用高斯分布,你也可以使用伯努利分布啦,一般用高斯分布靠谱一点而已。
如下图,我们已知通过高斯分布的方式采样了79个点,变量为二维,即最后使用向量表示
那如何求得高斯分布的参数呢?没错,使用上节讲的最大似然估计。注意:该高斯分布函数是对于多维变量的,与常见的一维变量的略有不同

上文算得的高斯分布,就是在已知某个类的情况下,该样本的概率,因此根据下图的式子,就可以求得该样本属于哪一类。

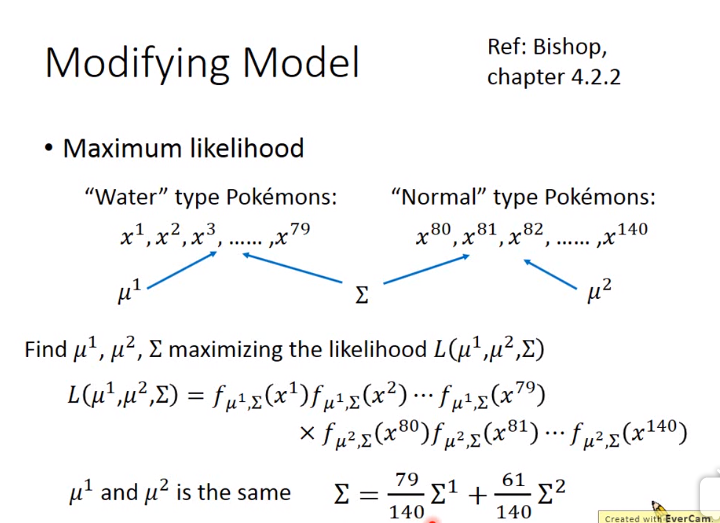
改进上述模型
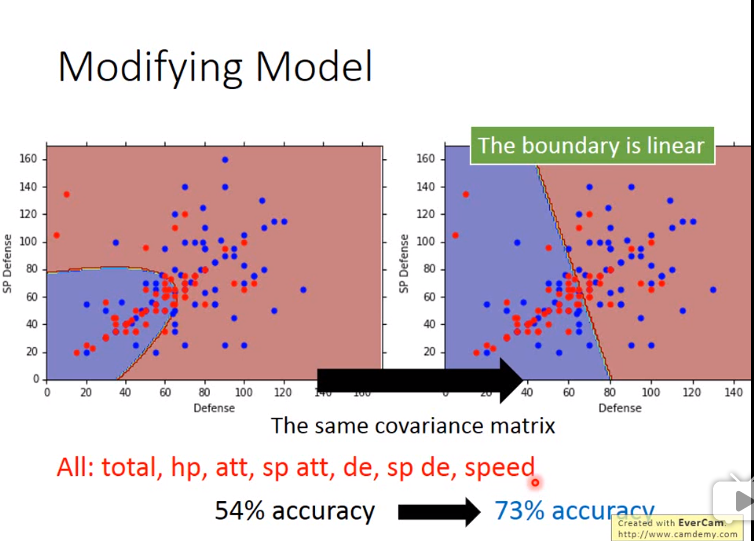
上述模型在实验效果并不是很好,故对其进行改进,使\(\Sigma _1 = \Sigma _2\),即共用一个\(\Sigma \)
然后正确率有了极大的提升,为什么???因为机器学习是黑箱,不知道啊。。。
12. 朴素贝叶斯分类
假设特征都是独立的,那使用朴素贝叶斯分类器就能给出很好的结果
13. 逻辑回归 VS 线性回归
逻辑回归的Loss function使用交叉熵,线性回归使用平方差,逻辑回归是判别式方法

逻辑回归的真实值为0或1,线性回归的真实值可以是任意数

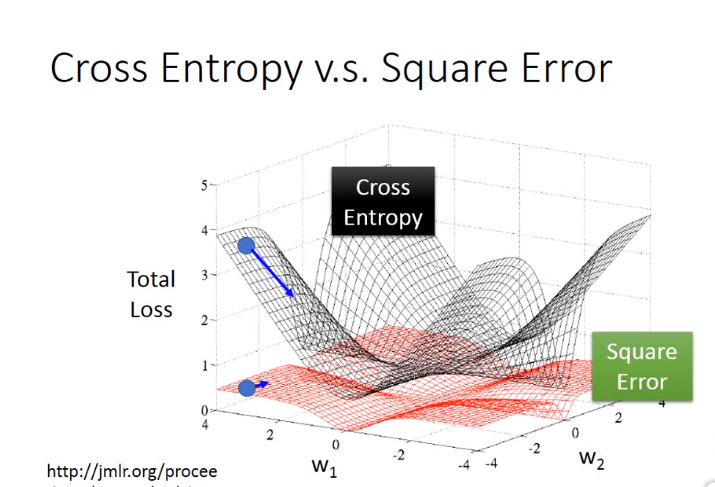
14. 交叉熵 VS 平方差
交叉熵是距离越远越快,平方差是距离越远不一定越快。
15. 判别模型 VS 生成模型

一般判别模型比生成模型精确度高
判别模型 VS 生成模型,生成模型使用朴素贝叶斯, 举例:
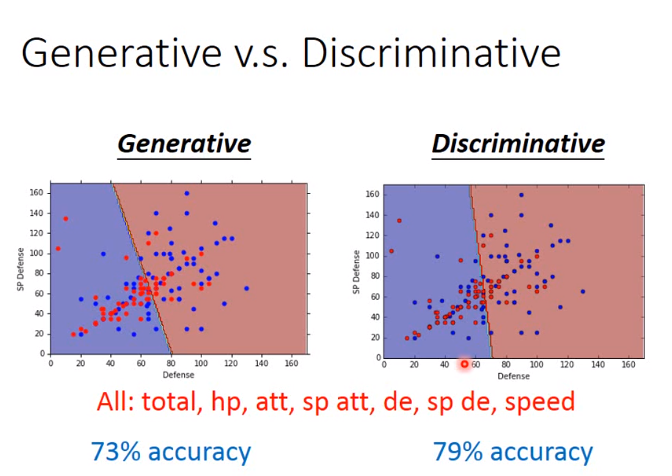

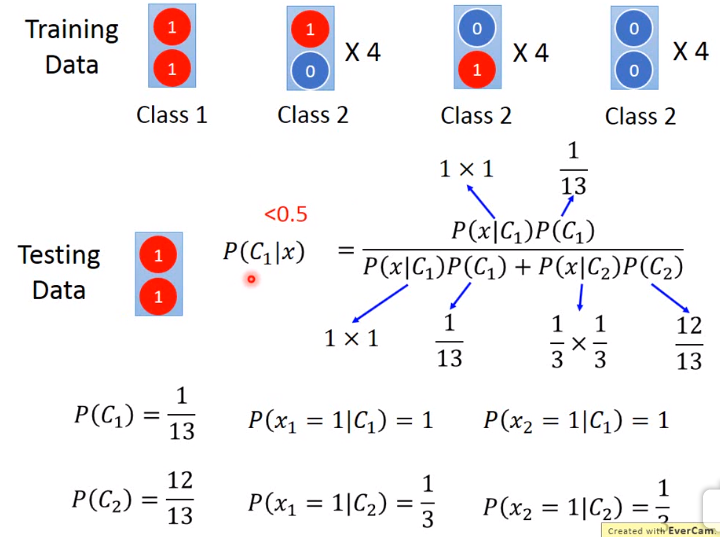
为什么生成模型不对,因为使用朴素贝叶斯,即假设特征之间相互独立,所以class 2的第一,二种情况,也有可能,并且生成模型有许多假设!
生成模型的优势

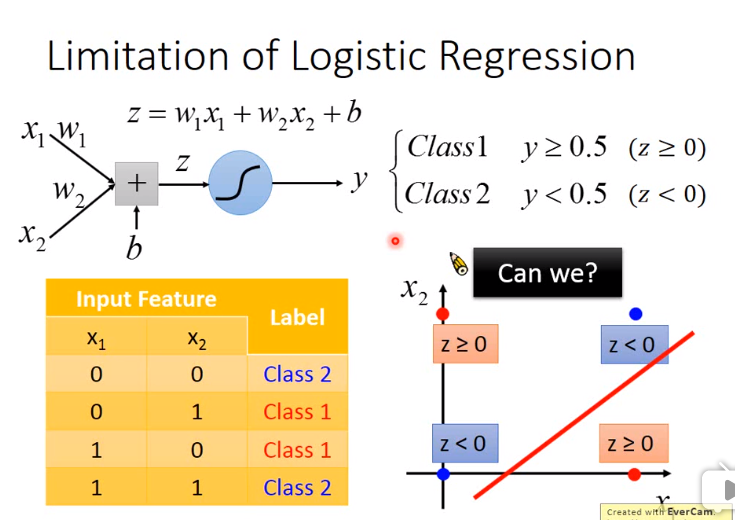
逻辑回归的限制
16. mini-batch为什么比SGD快?
因为一个batch里面有许多个样本,那么可以将这些样本整合起来成为一个矩阵。因此对于100个样本,SGD(即batch = 1)需要做100次运算,然而在batch size = 100的mini-batch中只需要进行一次计算!