半监督学习
半监督学习的在有label数据的情况下,还有许多远远多于label数据的unlabel数据,迁移学习和归纳学习是半监督学习,如下图:

有监督的生成模型
回顾一下全概率公式,贝叶斯公式和类条件概率。
全概率公式(P(B))是由’原因推结果’。
贝叶斯公式(P(A/B))是由’结果推原因’,即现在有一个’结果’A以发生,在众多可能的’原因’中,到底是哪一个导致了这结果”。
类条件概率(class-dependent probability,P(B/A)),类条件概率中的类指的是把造成结果的所有原因一一进行列举,分别讨论.
有监督的生成模型,一般是给出先验概率\(P(C_i)\),符合高斯分布的类条件概率\(P(x|C_i)\),求\(P(C_i|x)\)

半监督模型的训练方式
生成模型的训练方式
因为会有大量的unlabel的数据,会影响先验分布和符合高斯分布的类条件概率中的参数,所以不能按照有监督的方式训练
训练方式如下,训练方式类似于EM算法:
理论上是会收敛的,但是初始值会影响结果,可能会造成局部最优


self-training的训练方式
要使用self-training的训练方法,必须假设数据分布是low-density Separation。low-density Separation是指找到一个边界,这个边界可以明显区分且边界附近无data,也就是结果应该很好,不会出现模棱两可的状况
self-training的方法不能用于Regression(因为预测的值一定是在回归线上的,不会影响loss)
下图有一个错误,应该把”add them into unlabeled data set”改成”add them into labeled data set”

基于self-training的增强方法: Entropy-based Regularization
如下图:对于unlabel的数据,E(y)越小越好

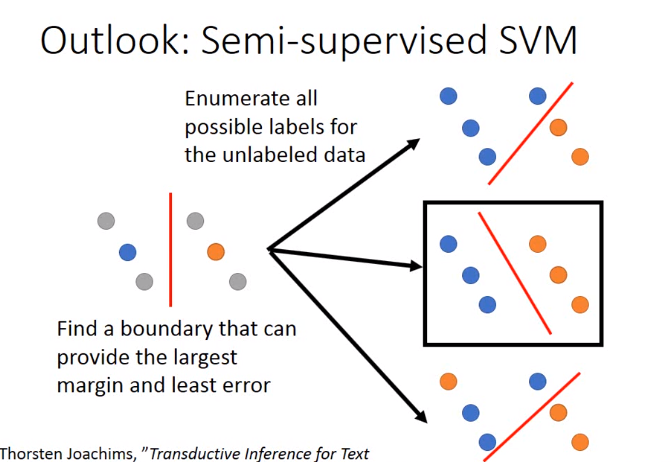
基于SVM的训练方法
如下图: the largest margin指的是让两个类别分得越开越好
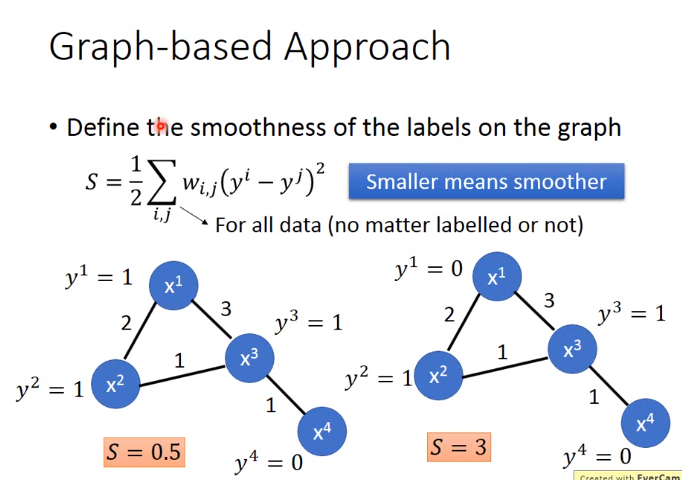
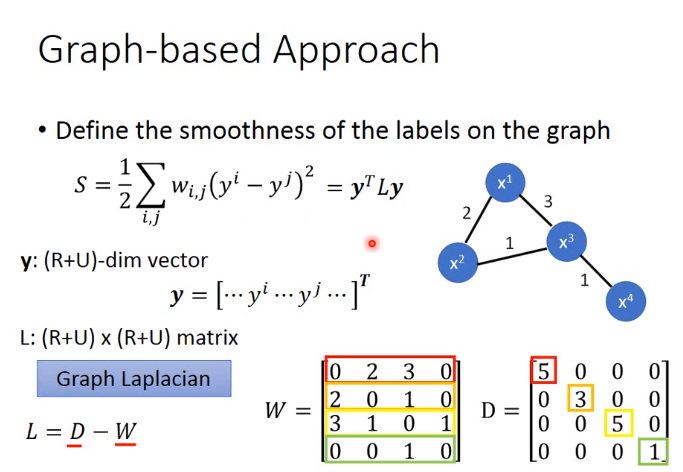
基于Smoothness Assumption

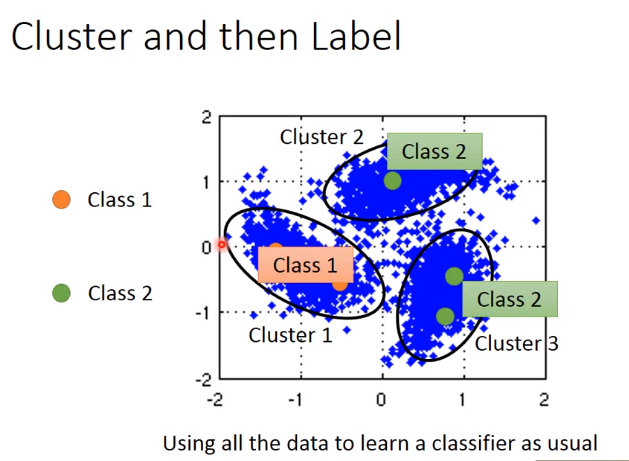
实现方式1-聚集(Cluster and then Label)
该方法需要Cluster很强,要有很好的方法描述Image
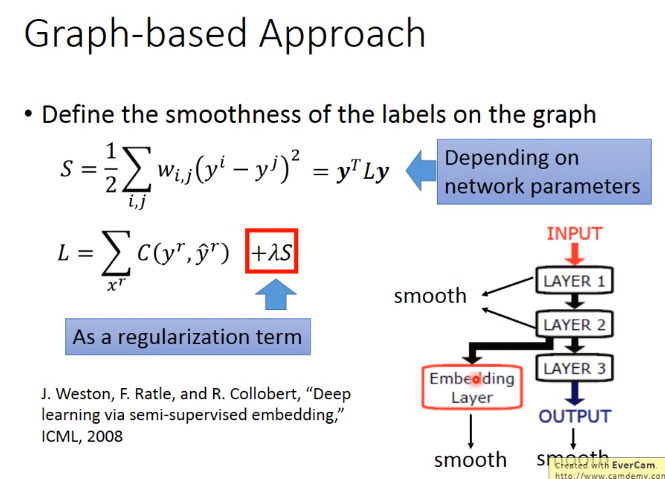
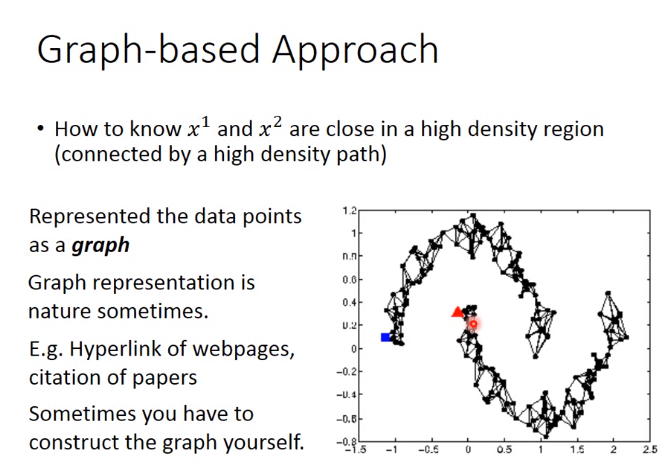
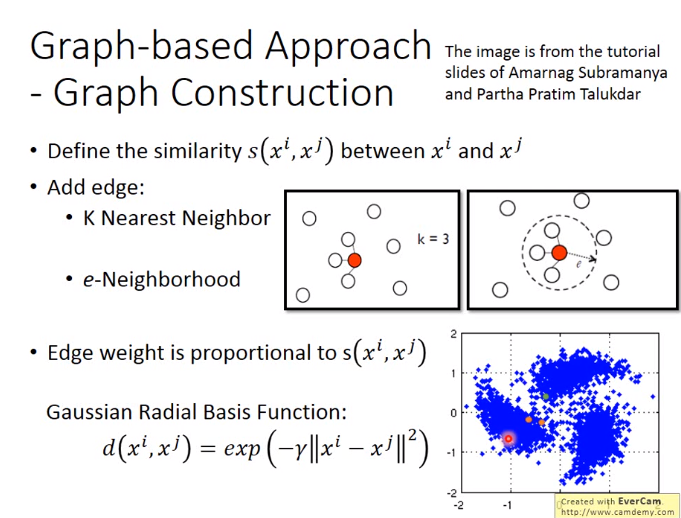
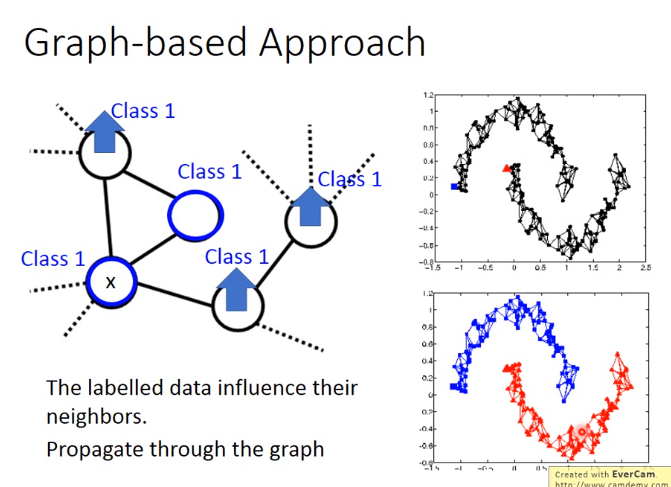
实现方式2-Graph-based Approach
下图中,应把d改成s
下图中 smooth并不一定需要在output layer,也可以是hidden layer,然后再做梯度下降即可