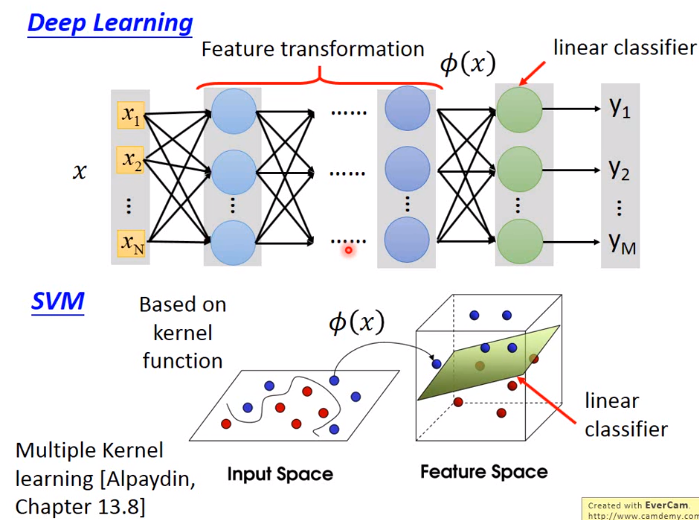
SVM
SVM = Hinge Loss + Kernel method
1.Hinge Loss
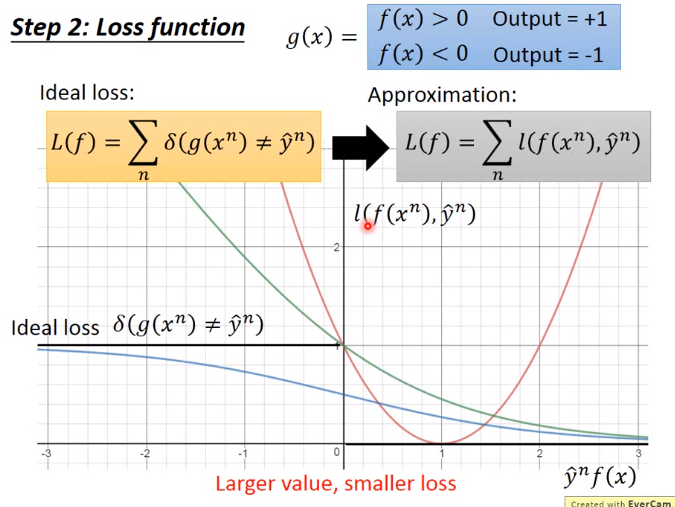
先回顾二分类中的问题

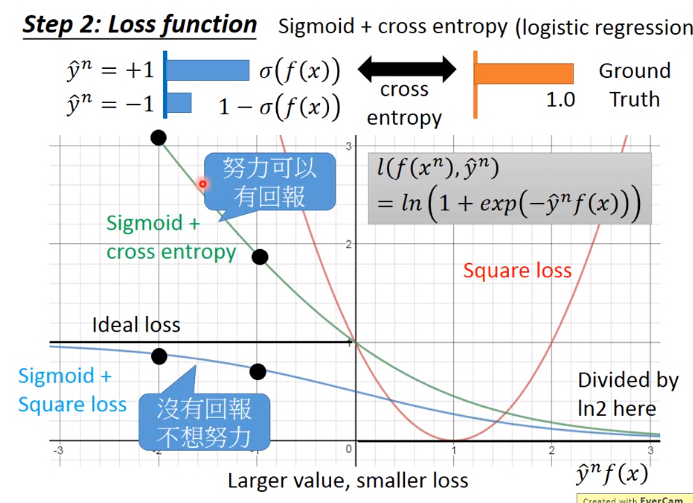
下图y轴为Loss,x轴为\(\hat{y}^n f(x)\)。在理想的情况下\(\hat{y}^n f(x)\)值越大,Loss就越小,因为\(f(x)\)越大就说明越跟label相匹配,loss就应该越小
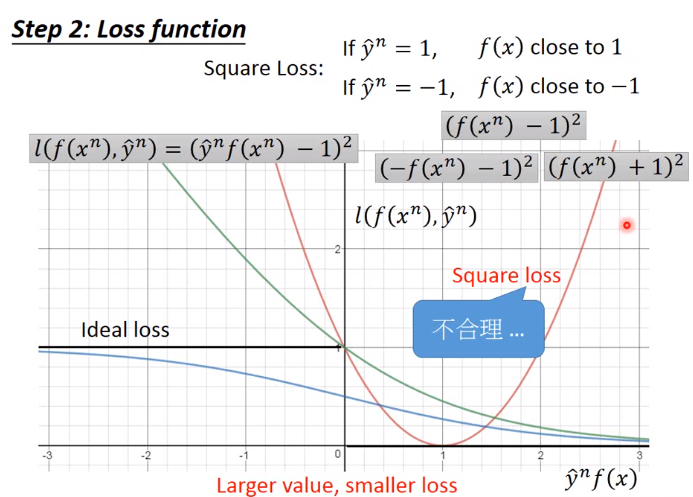
二分类问题中用square loss明显不合理,因为不符合Larger value,smaller loss的原则
下图的损失函数为红线
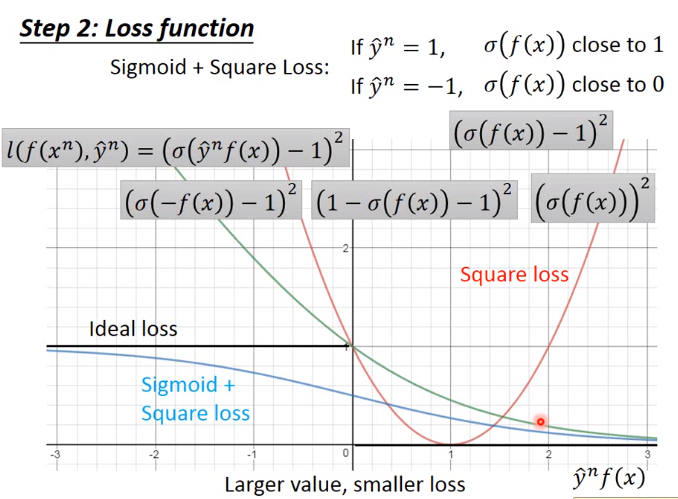
下图的损失函数为蓝线
下图的损失函数为绿线
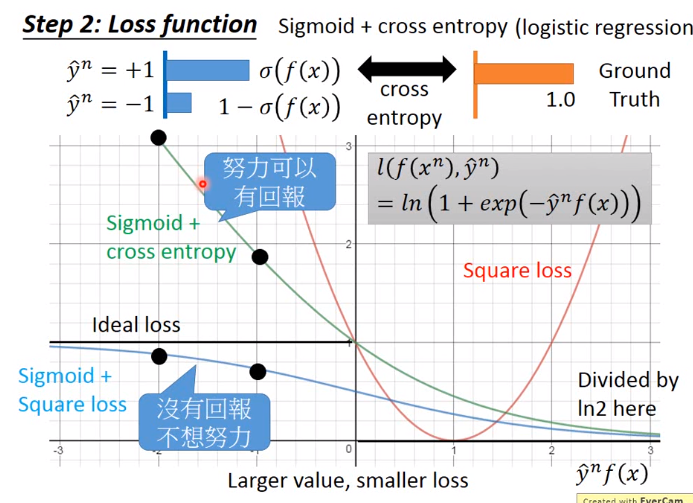
下图的损失函数为紫线
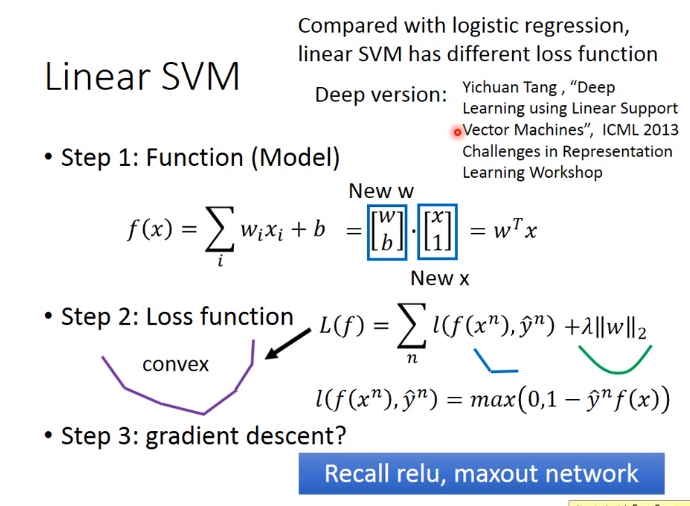
Linear SVM
如下图,梯度下降解SVM

实际上SVM也有另外的表示方式,一般情况下,上红色框不等于下红色框,因为
下红色框的\(\varepsilon^n\)可以为上红色框的\(max+1等等\),但是若加上minimizing这个限制,那么其只能等于\(max \)
2.Kernel method
继续沿用上节的Linear SVM 找出的\(w\)即model是data point的线性组合
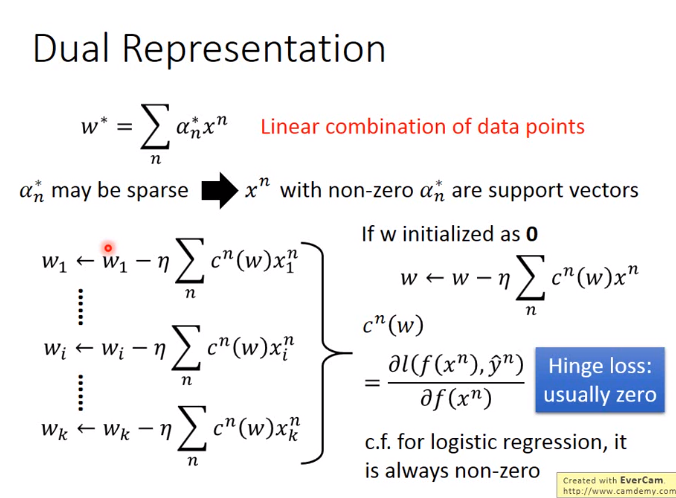
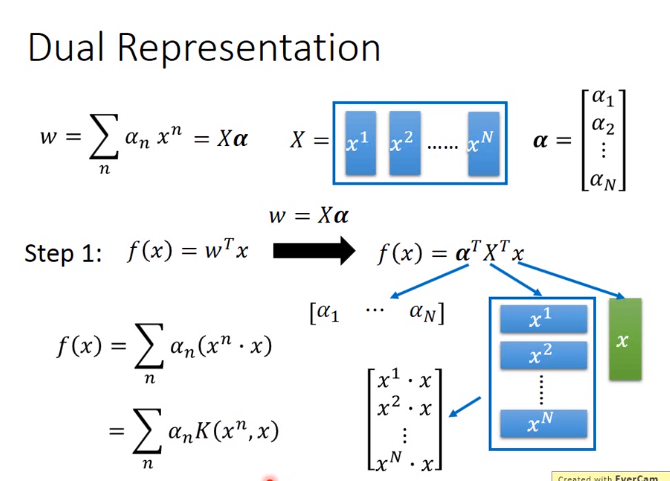
\(\alpha_n未知 \),所以下图是找到\(\alpha_n\)使loss最小

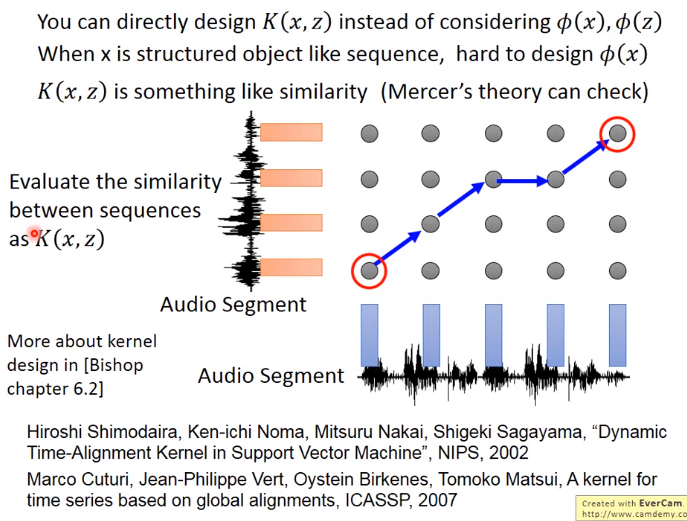
根据下图,有时,直接计算\(K(x,z)\)会比特征转换后再做inner product更快


下图中,\(K(x,z)\)是 计算\(x和z\)的相似度,最后将\(exp(x·z)泰勒展开\)

下图把第一个\(\alpha_n改为\alpha^n\)
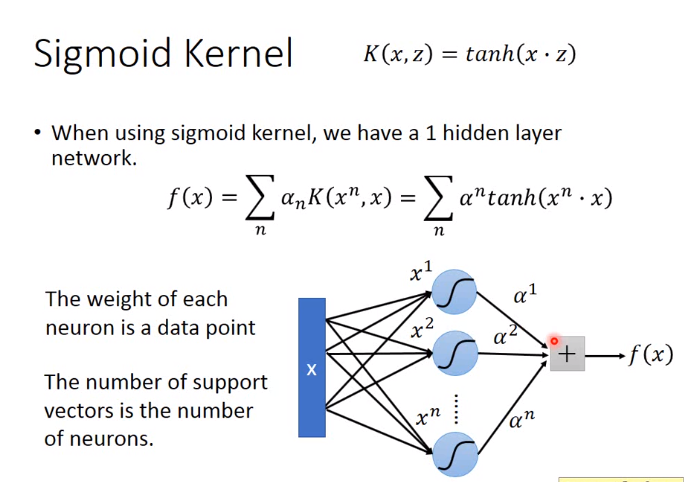
3.总结SVM
先通过kernel函数将data的特征转到一个high dimension上,然后再high dimension上使用linear classifier(使用Hinge loss)