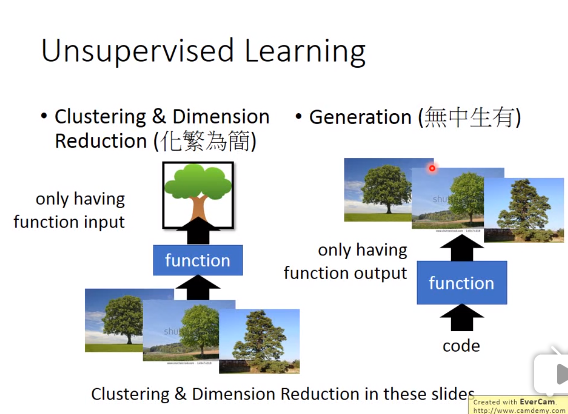
Unsupervised Learning
Unsupervised Learning一般有两种方法:clustering&Dimension Reduction和Generation
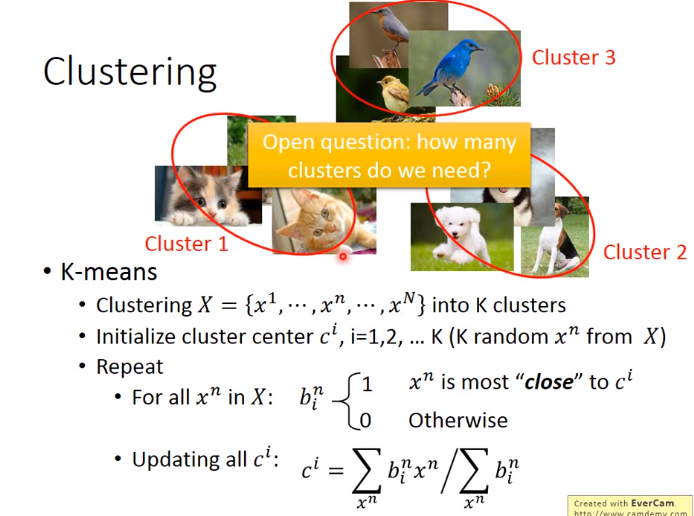
Clustering
Clustering也有许多方法,介绍如下:
1. K-means
2. HAC(层次凝聚聚类)
相比较于K-means,适用于不知道该分多少个K类的情况
Dimension Reduction
Dimension Reduction也有许多方法,介绍如下:
1. Feature selection
选取一个符合所有数据的特征,但是一般不常用,因为往往特征之间有关系
2. PCA(流行的降维方法)
一般使用在线性的情况下
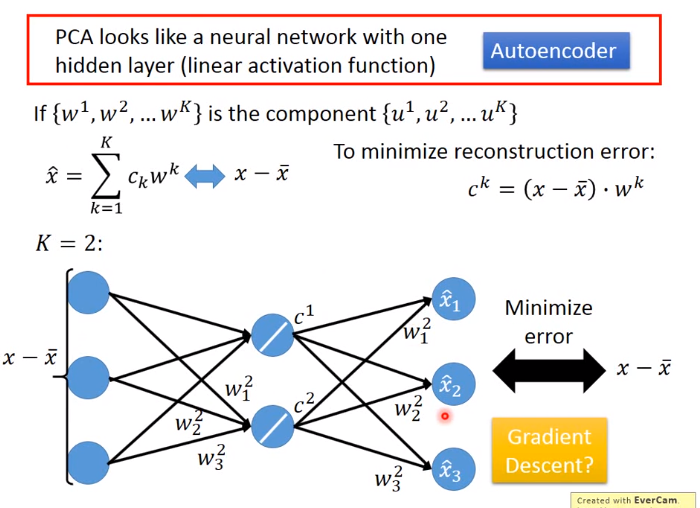
目的: 找线性函数\(z=Wx\)的参数\(W\).PCA可以看做有一层隐藏层的神经网络
PCA可以解耦,即把一些有相关的特征给去相关,减少参数量,避免overfitting的情形
PCA是找出代表样本差异的综合性指标
如下是推导:
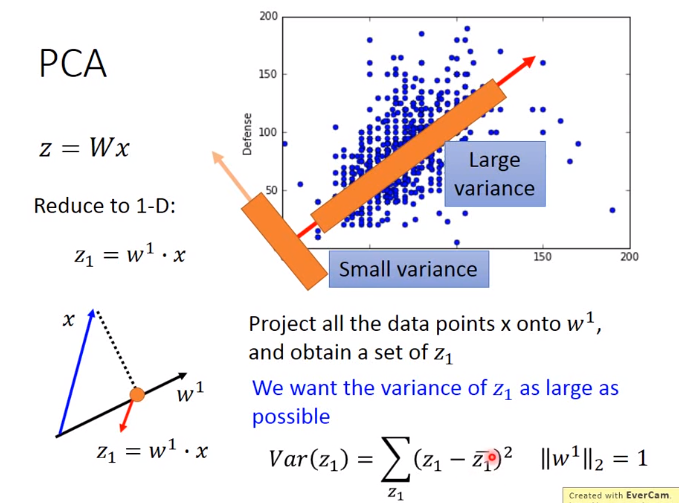
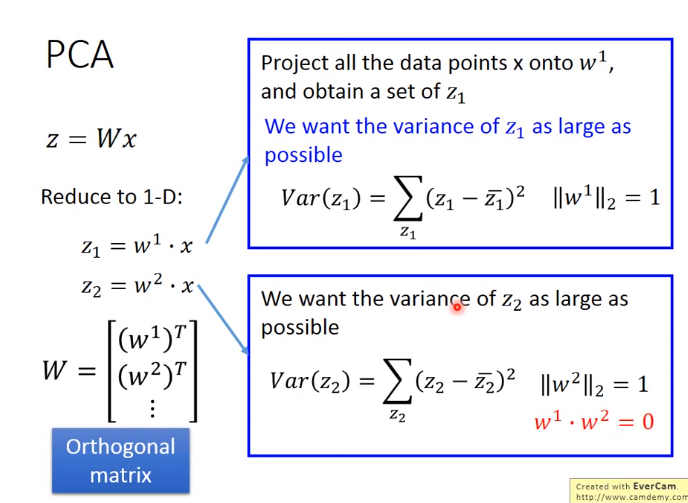
下图中\(·\)表示点积是一个数,蓝框是求和部分


结论:\(w^1\)是协方差矩阵S的最大特征值的特征向量,\(w^2\)是协方差矩阵S的第二大特征值的特征向量
如下图所示,PCA可以看成是只有一个隐藏层的NN,它可以用梯度下降的方法解吗?
不能!因为使用PCA之前求的是特征向量,它要求特征向量之间是正交的,梯度下降却是做不到的,而且之前已说明使用SVD分解的话效果是最好的,梯度下降方法不可能比SVD分解的效果更好
PCA缺点
- unsupervised. 即数据都是unlabel的,若将下图的数据投影到一维的情况下,需要找到让data的variance最大的dimension。但是若数据实际上是有分类别的,那么在PCA投影到一维上时,会merge这两个不同的类,无法分辨。LDA是考虑label data的降维方法,是supervised的,可用于解决上述问题
- Linear. PCA只能做linear的dimension reduction,不能做non-linear的

一般PCA之后的component是之前图片的一部分,但是有时候不是,为什么呢,如下图,每个component前的参数\(a_i\)可以是任意值,这就会造成component的加或者减,这就会导致并不是之前图片的一部分

3.Matrix Factorization
对稀疏table进行分解,可以对空白的地方进行推荐,下图中\(r^A表示行,r^1表示列,5是表格的原有值\)


4. word Embedding
word Embedding: 机器通过使用无监督学习,在阅读了许多文档的情况下可以学习单词的意思,并且单词可以通过上下文来理解。
word embedding的训练是unsupervised
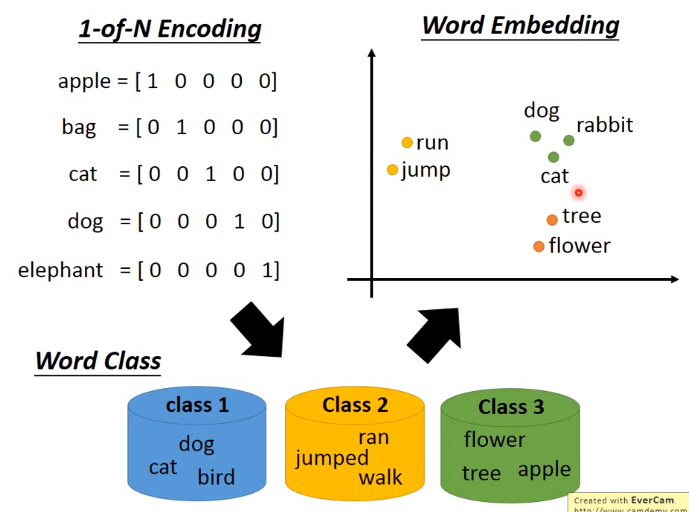
对于如何利用上下文,一般有两种做法:1.count based 2. Prediction based
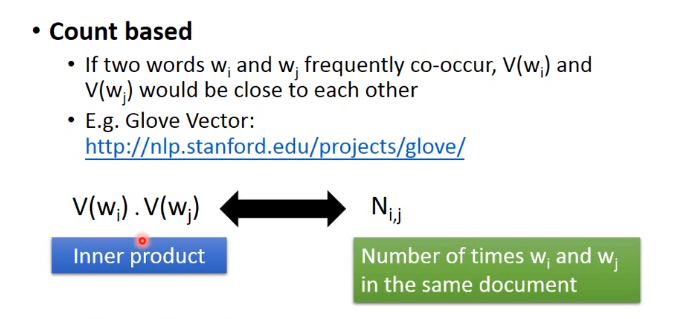
count based
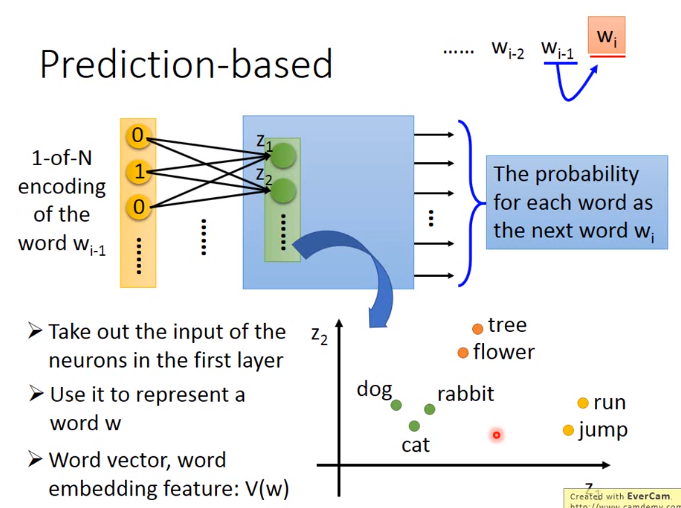
Prediction based
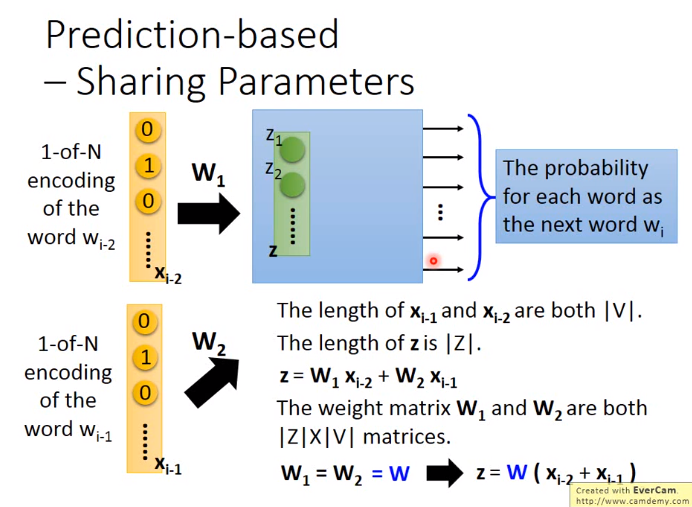
如下图,用\(z\)表示词的向量,即在第一个隐藏层之前的未做激活函数的值。实际上在word vector上不用deep的模型,只是用shallow的,且激活函数为线性的模型即可,因为它实际上是在抽特征,然后再到另外的nlp领域,若用deep的模型,时间太慢。
考虑到需要之前多个词的情况,即共享权重,类似于CNN,如下图

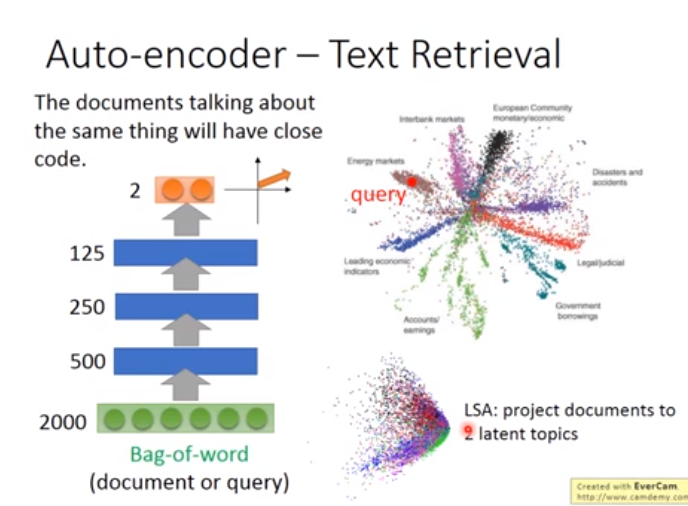
拓展:document embedding
下图用了一个AutoEncoder
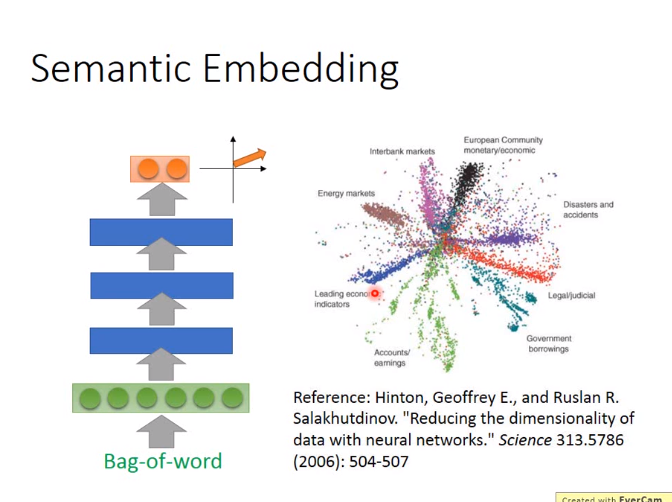
Bag of Word就是统计某一个单词出的次数,出现了多少次,该维度上的值就是多少
Bag of Word的缺点:

5. manifold learning(流形学习)
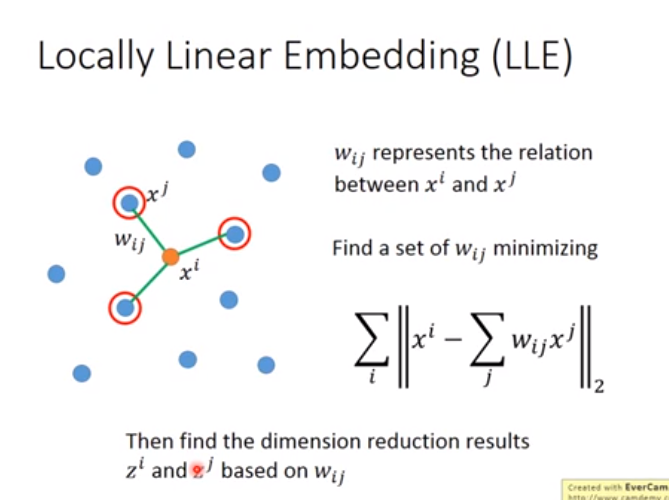
方法一 LLE(Locally Linear Embedding)
如下图\(x^j是降维后的,x^i是降维前的,x^i和x^j均已知,w_ij是权值\)
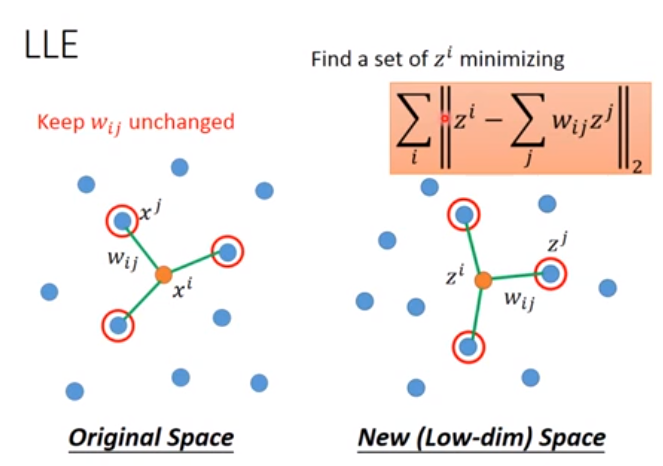
然后固定\(w\),找到降维后的结果\(z\)
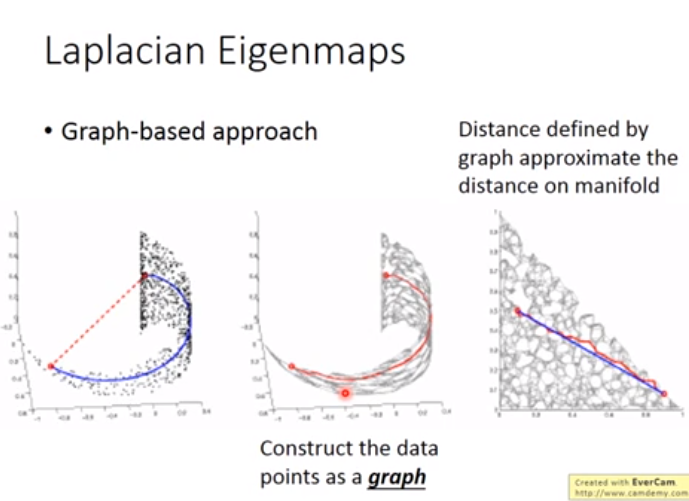
方法二 Laplacian Eigenmaps(拉普拉斯特征映射)
使用图距离的方法代替欧几里得距离做降维
对于监督学习,损失函数如下图,其中S表示两个label越近越好
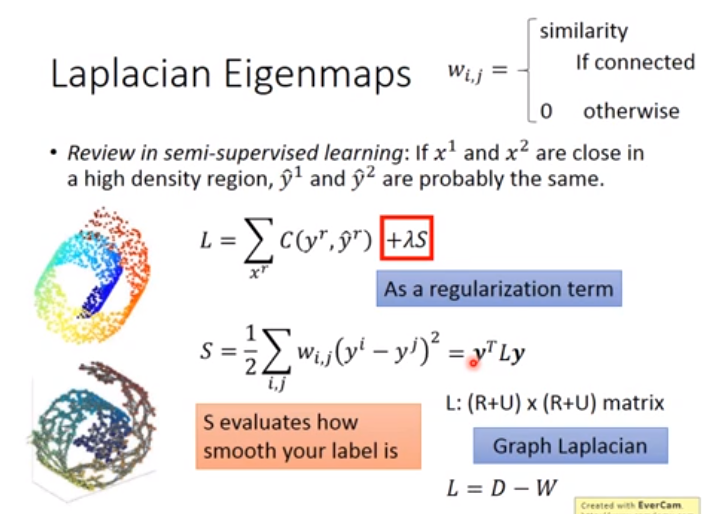
对于无监督学习,如下图,s是所求的损失函数,该损失函数需要满足一个约束,即如果降维后的结果z的维度为M,那么需要降维后的z填满降维后的空间个人觉得应该是\(z^M不是z^N\)

注意:方法一和方法二均要求降维之前的很近的点再降维之后也要很近,并没有对距离远的点作要求,如下图:

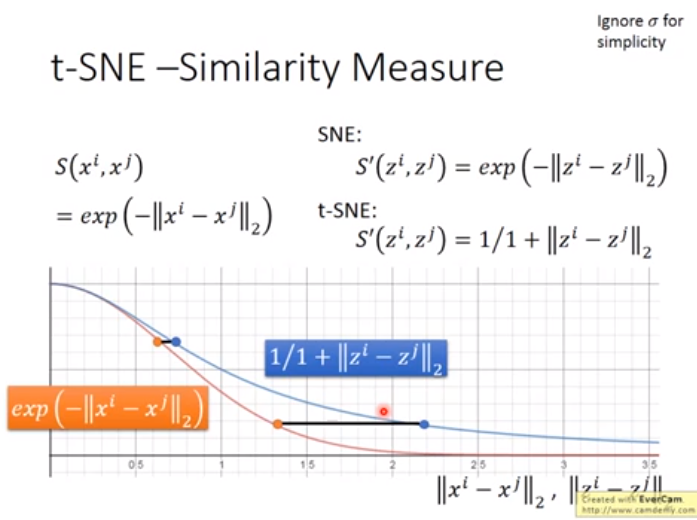
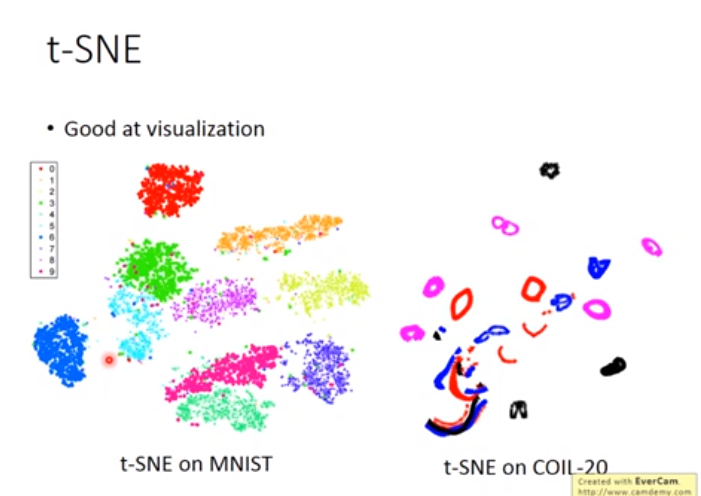
方法三 t-SNE(流行的降维方法)
易于将高维数据降维后可视化
其中p是概率,t-SNE表示降维之前距离近的降维之后也要近,降维之前距离远的降维之后也要远

在t-SNE时,之前有gap的,降维后gap会放大
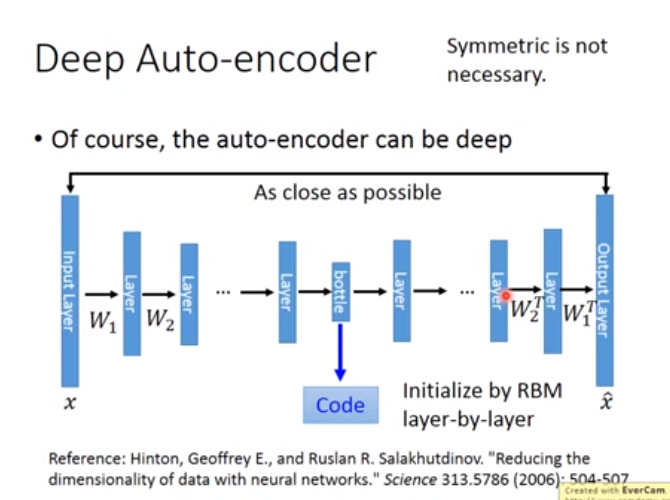
6. Auto-encoder(非监督下,神经网络的降维方法)
对Image进行降维成code,目的是要code好,并不是error越低越好
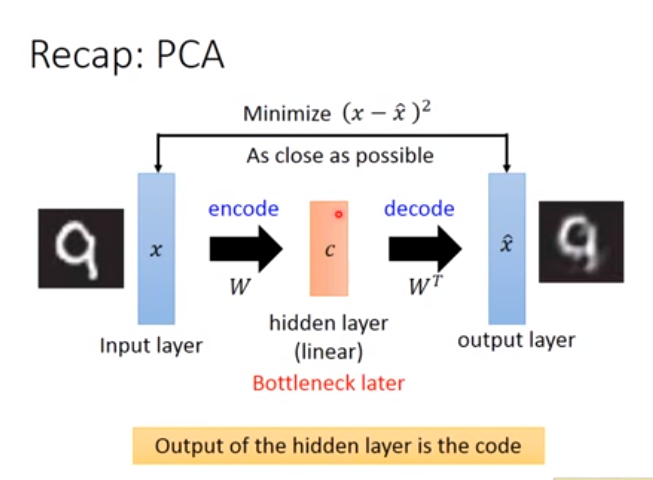
在下图的PCA中,隐藏层的输出是code
用途1. 用Auto-encoder做CNN
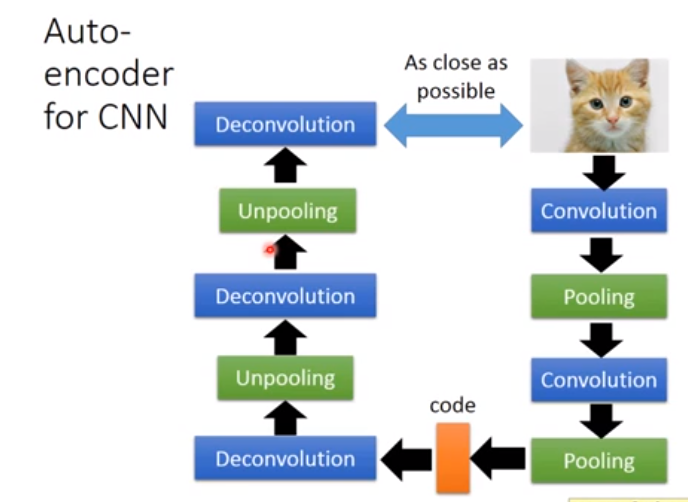
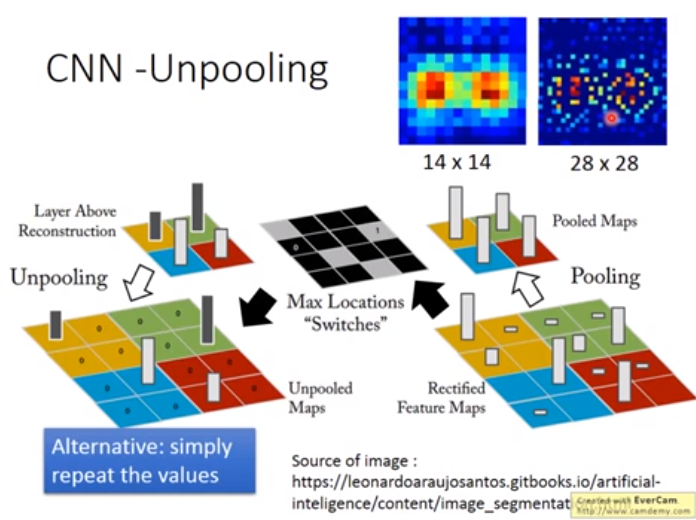
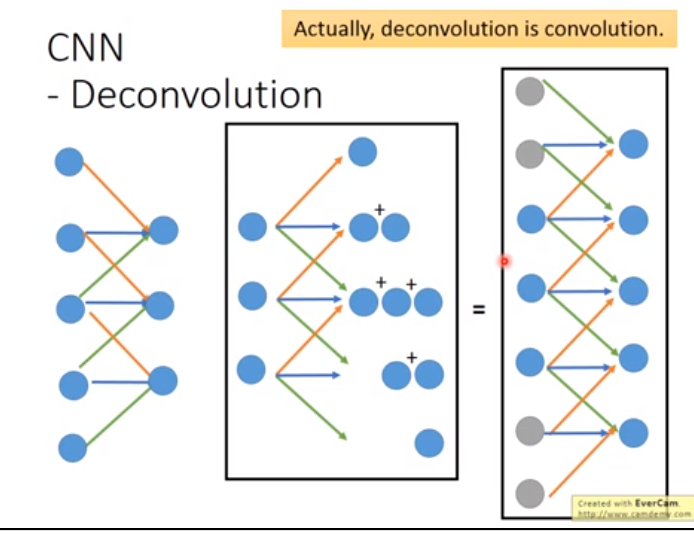
Deconvolution就是convolution
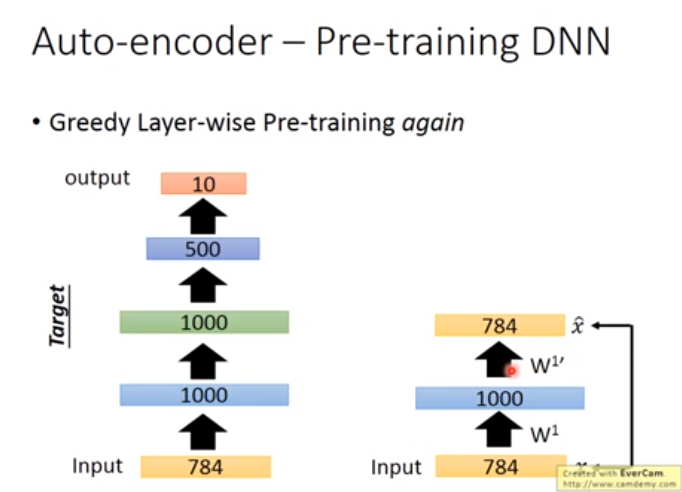
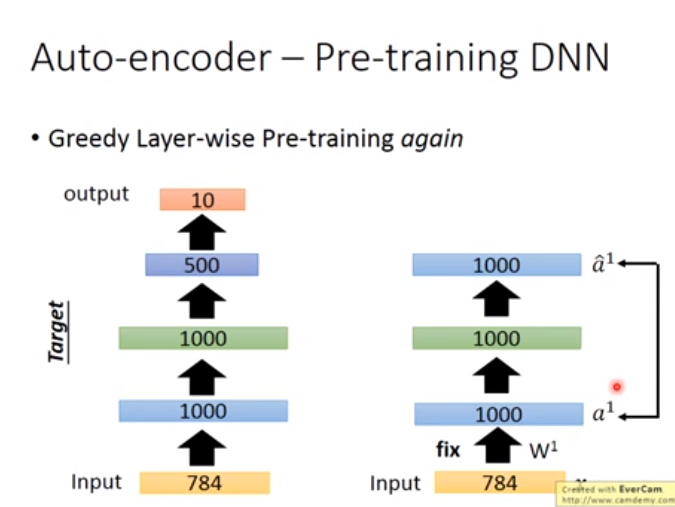
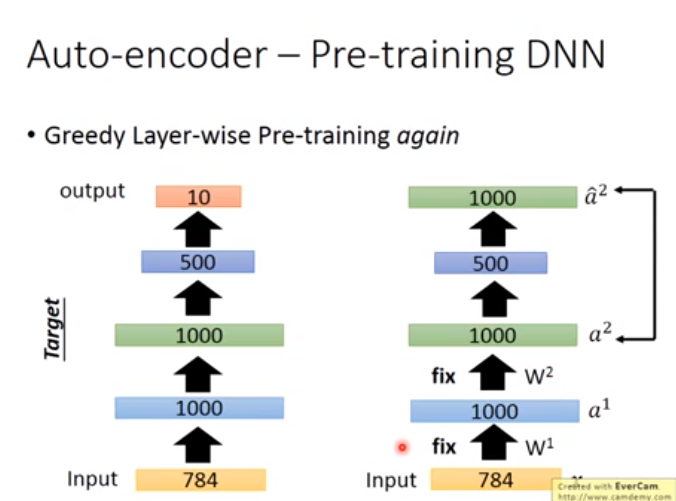
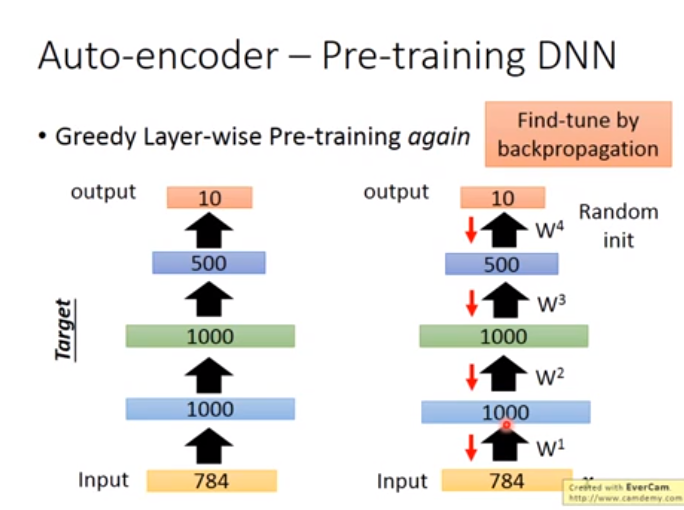
用途2. 用Auto-encoder Pre-training DNN(Auto-encoder与有监督的方法结合)
如下图右边,一般用Autoencoder其隐藏层维度应该较小,因为需要与目标第一个隐藏层维度一致,因此面对高纬度下的Autoencoder,需要加正则化或者是noise,否则不会训练出好的参数\(w\),然后以以下这些图的方式来训练Autoencoder