生成模型
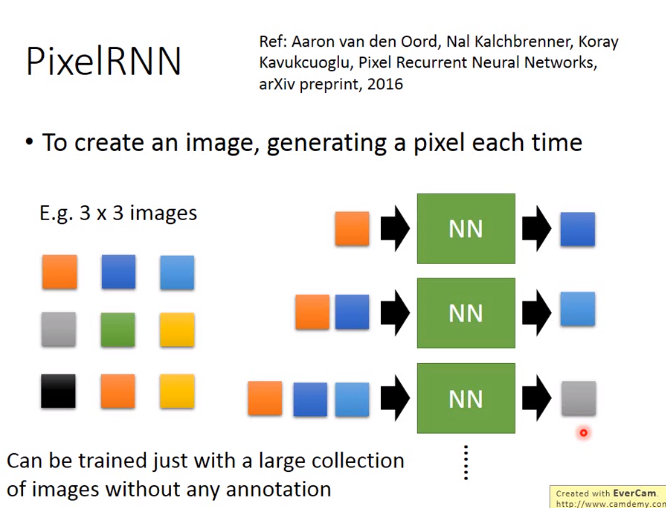
1. Pixel RNN(2016年提出)
如下图,输入和输出都是三维的向量,表示RGB这三个值。但是一般效果不好,实际上会用one-hot的格式来表示一个像素,一个维度表示一种颜色
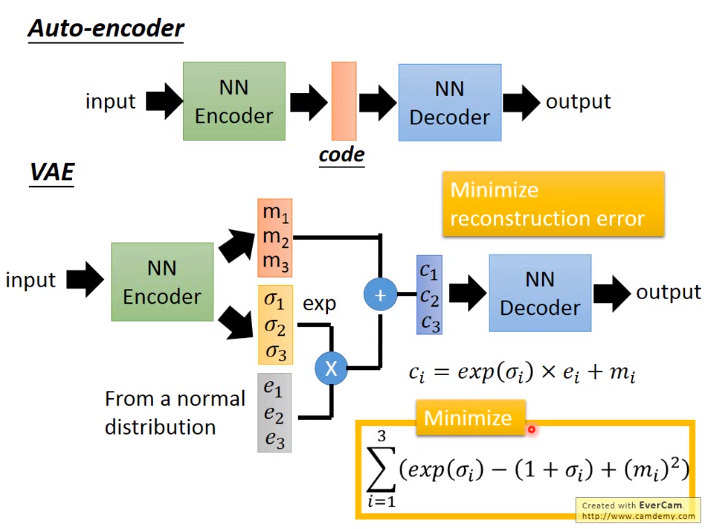
2. VAE(2013年)
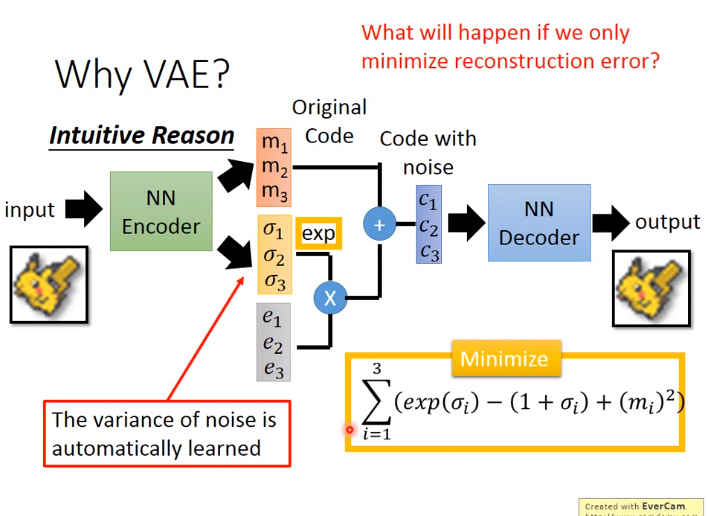
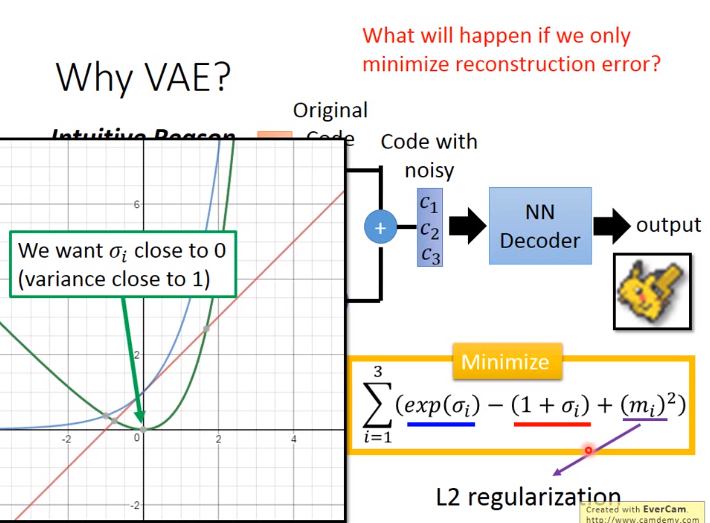
下图中:\(m\)是原来和AutoEncoder一样的code,\(c\)是加噪声后的code,\(\sigma \)是noise的方差,代表noise应该有多大是自动学习得到的,后加\(exp\)确保一定是正数。在有损失函数后也需要对方差做一个限制防止机器训练后使\(\sigma = 0 \)又变为Autoencoder
VAE与Pixel RNN的不同:
VAE理论上可以控制你要生成的图片
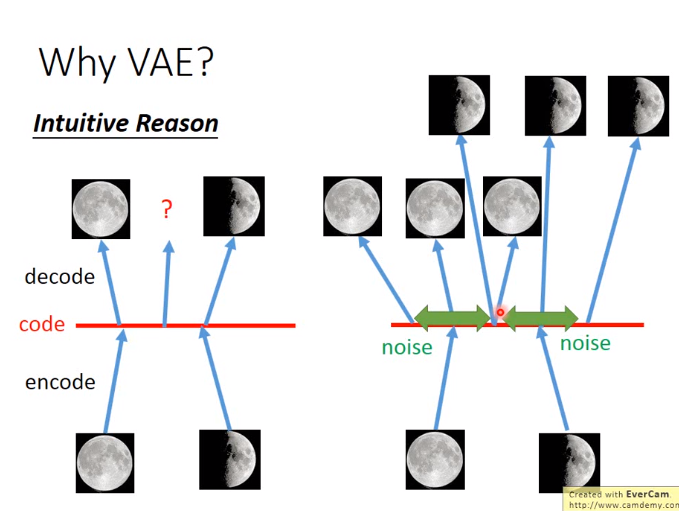
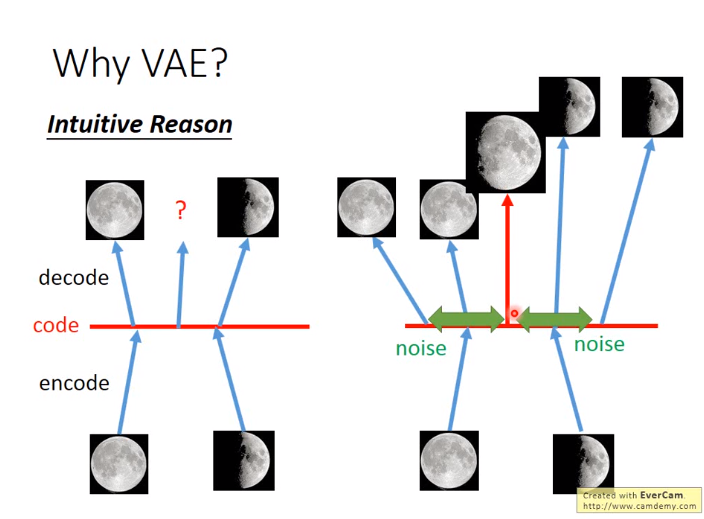
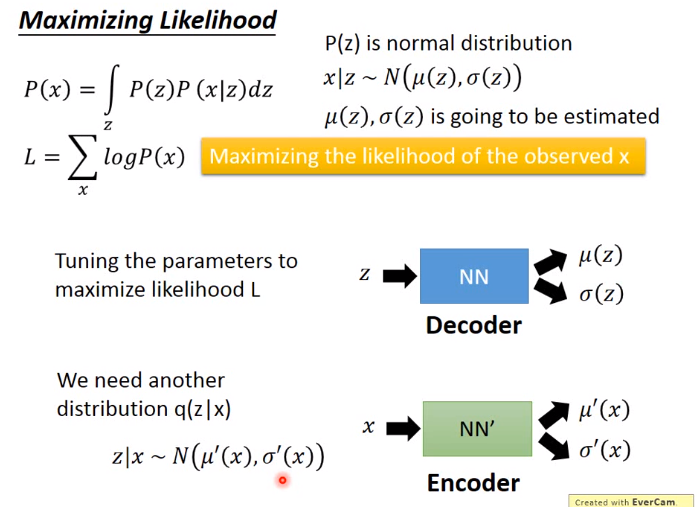
为什么VAE?直观如下:
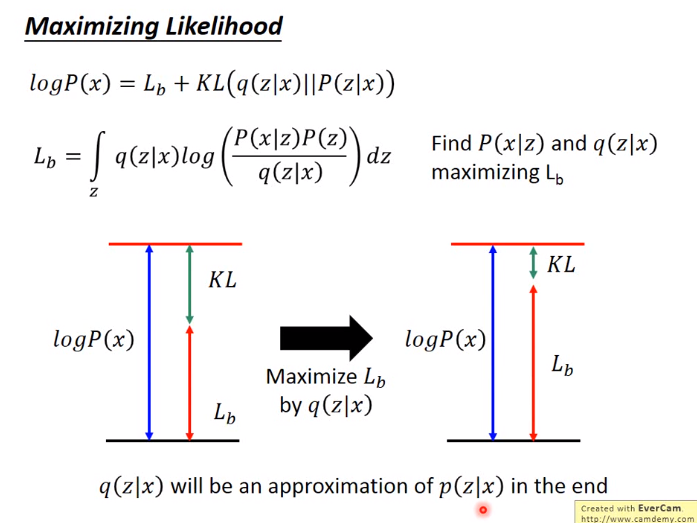
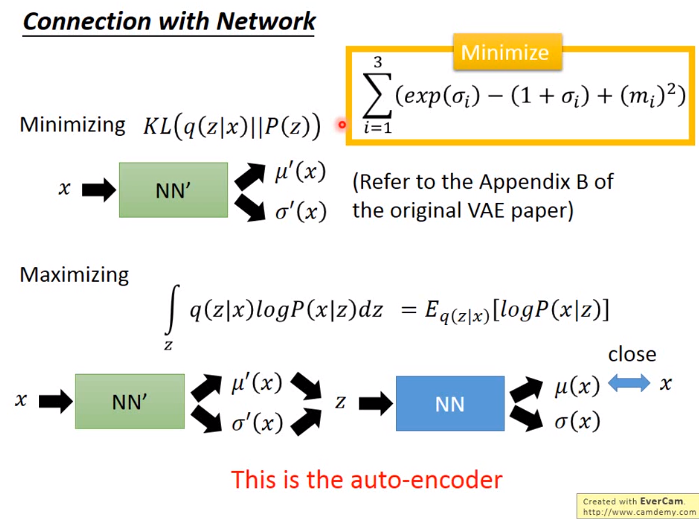
VAE证明(没怎么看懂):
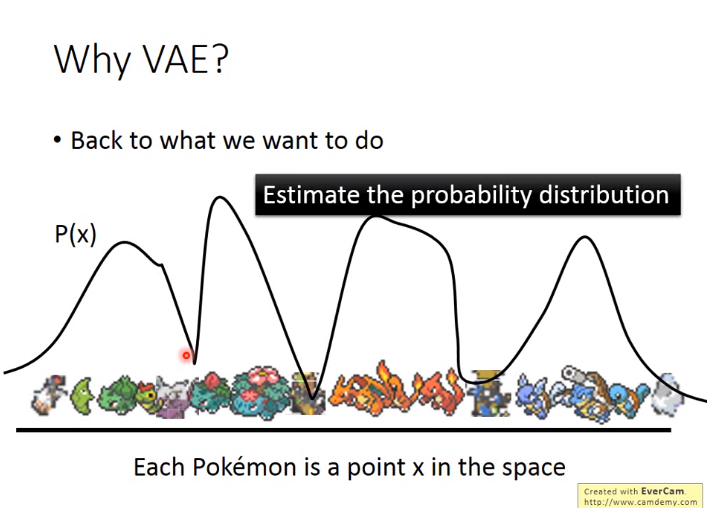
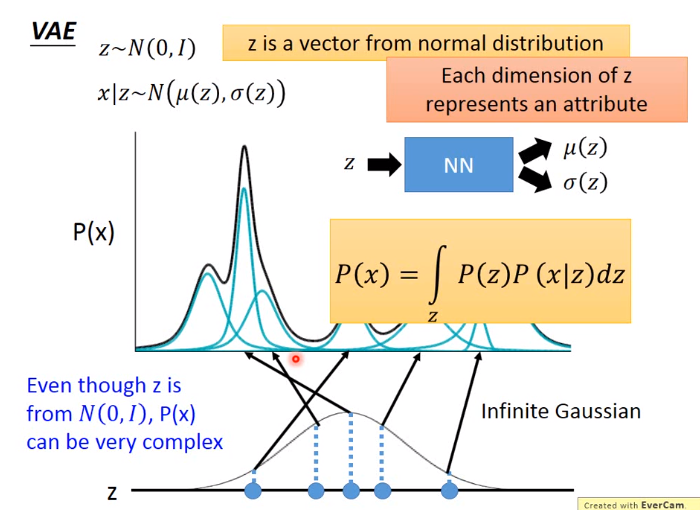
VAE的目的最后是生成图片,即在一个分布下找到一个图片即可
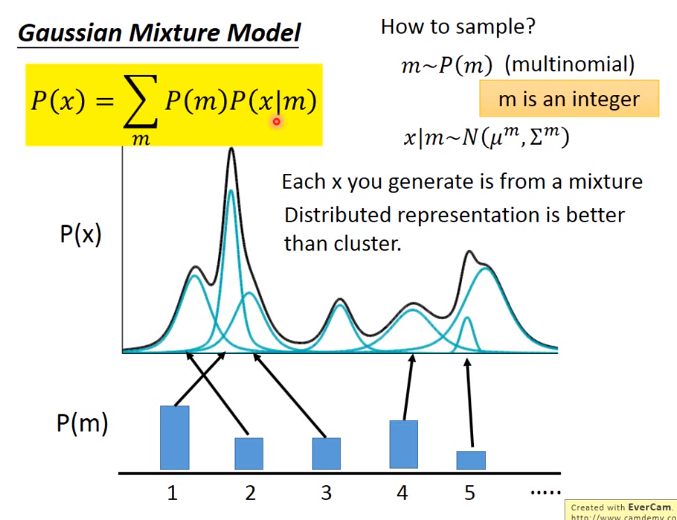
下图\(m\)表示第几个高斯分布
借鉴高斯分布,在下图的VAE中,假设\(z\)是一维的,在符合\(N(0,1)\)分布的高斯分布中取得\(z\)之后,通过神经网络NN学习符合在\(x|z\)分布下的高斯参数\(\mu和\sigma\),最后求得分布\(P(x),P(x)表示已有Image的分布\)


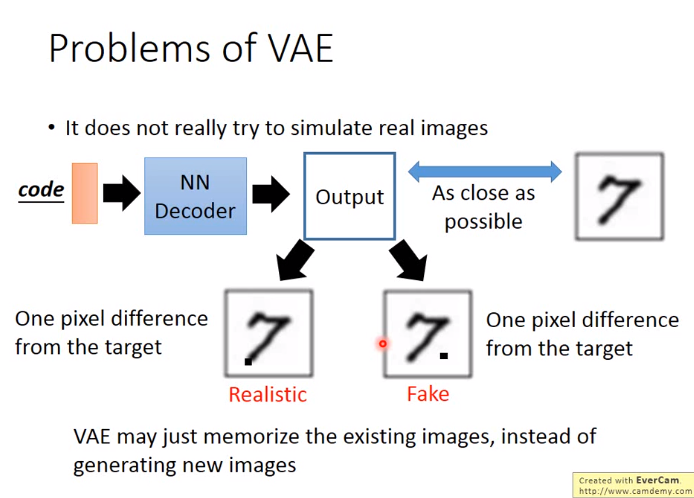
VAE的问题
VAE只是尽量去模仿数据库中的图片并不会去创造性的产生新的图片
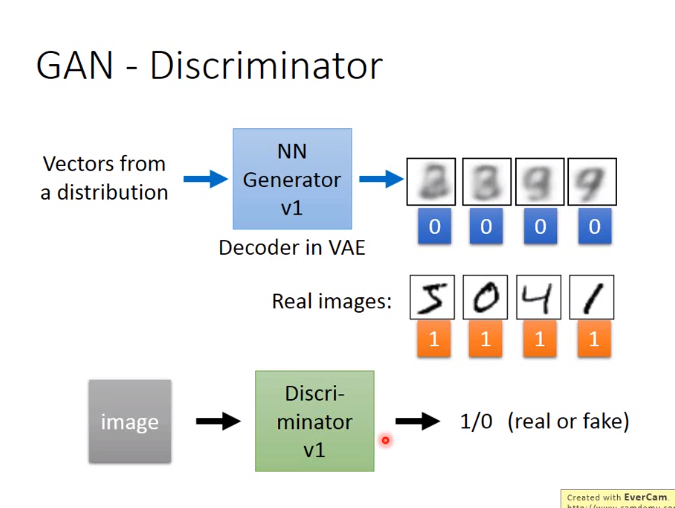
3. GAN(2014年)
下图使用二分类的方法训练Discriminator
在训练Generator时要固定Discriminator,因为Discriminator的输出想要为1,即判断为真,那么只需Discriminator中的bias设置为1,weight都为0即可。
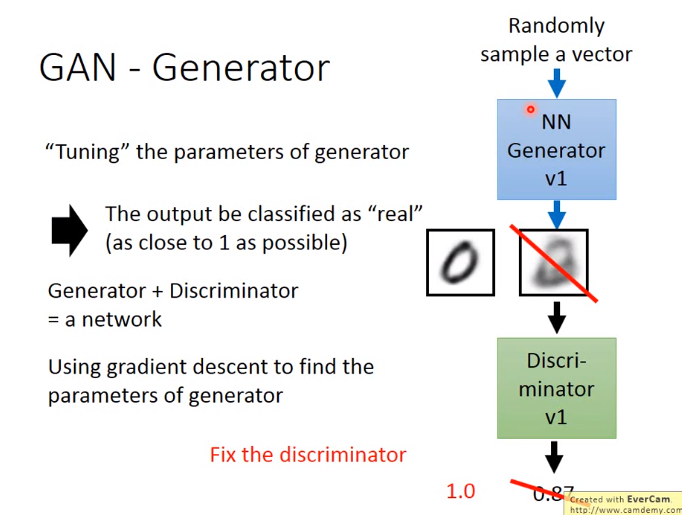
GAN有个缺点:需要判别网络很好才可以,如果判别网络效果差,那么整体效果也就差